
Introduction
Whether considering what to sell to whom and at which price, or in which order to visit different cities, scaling-up decision making processes can become quite complex, as the number of possibilities suffers from combinational explosion, and there may be no clear way a priori regarding how to go about it.
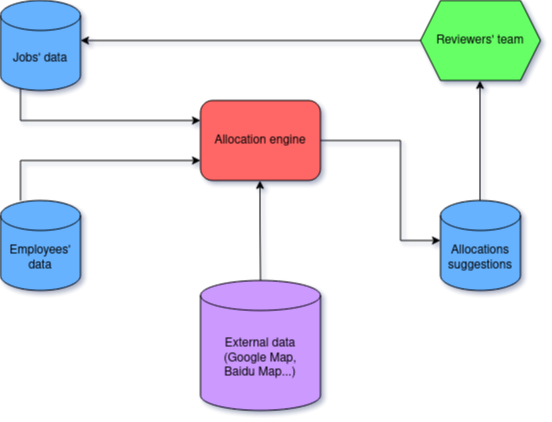
One of the tasks that a company may have to perform is deciding where and in which circumstances to send the appropriate workforce to tackle a planned job.
Let’s say that there is a list of jobs to perform every day, each one with their own skill requirements, and located at different places over a given territory. The company has employees located over this territory as well, with different combinations of skills and level of skills to tackle those jobs. A problem to be solved is then to decide who to send to which job; respecting, among other things, skills constraints; making sure that as many jobs as possible are covered; all while minimizing the costs associated to allocating an employee to a job (notably the duration and cost associated to travels).
This is an operational task that we have to deal with at QIMA, and in this article we will explain how we went about it, by modeling and solving the task as a Mixed Integer Linear Programming problem.
Points of interest to retain
Here is the gist of what we have learnt while working on this project, or which can be useful to retain from this article:
- The known tricks to use in order to represent a non-linear optimization problem as a linear one
- The possibility to somehow work around a salesman-like problem's combinational explosion issue, by modeling geographical zones as cliques of the graph of locations
- The existence of DropSolve / WatsonIBM, and the ecosystem of other optimization problems solver solutions in general
- The use of Baidu’s API to automatically fetch info about possible travels between different locations in China
Modeling the problem & impact of the chosen solver
Since we are takling about which set of decisions to take in order to reach the best outcome possible, while accounting for constraints, this task naturally lends itself to being modeled as an optimization problem.
Within that frame, we are representing the decisions to be taken as variables which can take specific values, we are defining the objective function F to be optimized based on those variables, and we are translating the operational constraints into mathematical constraints for those variables.
Here, a decision is basically “Assign this agent A to work on this job J on this given day D”, and the engine's job is to find the best set of decisions for specific jobs and agents to cover the jobs to be performed on a given day.

Objective function & Constraints
For our optimization, we decided that it should be a minimization problem, so the objective function is defined as ‘total costs – total gains”.
Gains are based on the value associated to the completion of each job. Ideally, each job should be completed as scheduled; postponement should be undertaken only as the very last resort. Also, there are jobs which have more priority than others, so the gain should reflect this, so as to encourage the solver to allocate for them in priority. Sometimes the allocation engine will not be able to allocate every job; the needed decisions are then deferred to the human team which supervises the work of the engine.
Costs covers a variety of different aspects of the decision taking problem. A cost can be associated to:
- The choice of an agent in itself (daily fees if temporary workforce...)
- The cost of sending an agent from their home location to the job’s location (fees...)
- An internal preference of the company for employee allocations (ex: to take into account employees current occupation rate, estimated tiredness level, etc.)
- The definition of penalties, so as to allow the model to have some flexibility regarding its choices. It can be used for example to allow the model to break some rules in order to maximize the coverage of allocated jobs if there is no other way to do so, while telling it that it should not do so if it’s possible to achieve the same result while respecting those rules.
The constraints are there to limit the scope of legal allocation decisions that the model can make. Notably:
- An agent must have the required skill level to be allocated to a job.
- An agent must be available on the days the job is scheduled.
- The workload that an agent can tackle during a single day is limited.
- An agent may be forbidden to be allocated to a job; or sometimes special requests are made so that an agent must be allocated to a specific job.
- Only complete job allocations are allowed, it’s useless to allocate agents on a job for some days if it will not result in the completion of the job.
- Other specific, temporary, ad-hoc constraints may need to be defined
Solver specifications & Optimization problem modeling
Operational specifications
Once we have this in mind, we need to think about the specifications of the solver solution, and the conditions in which the optimization tasks will be used.
In our specific use case, the optimization tasks, and the allocations propositions which result from it, must then be reviewed by a team of people which has the final word on the decisions taken. Moreover, the list of jobs to be allocated, as well as the characteristics of those jobs, keep evolving during the decision process for the jobs of a given day, so there must be a back-and-forth between the optimization process, and the review process. That means the time allocated to the decision process must be kept short enough so that this back-and-forth can occur often enough. This in turn means we want to stop the solving engine after a given amount of time, and ask it to provide us with its best current solution of the time. At that point we want to be able to evaluate how close we are to the optimal solution, even if we did not reach it.
For those reasons, we want to keep the optimization problem formulation as simple as possible, so as to have mathematical guarantees regarding the solving process, and the suboptimal solution when we force the engine to stop early.
Notably, here we keep the model linear, and the decision variables are binary variables, so we define the optimization problem as a Mixed Integer Linear Programming problem. The decision variables are binary (either agent A is allocated to job J on day D, or the agent is not). This also has the advantage of increasing the pool of existing solutions to choose from, regarding the choice of the solver.
Dealing with non-linearities
However, assuming we only have the decision variables defined above, then there are non-linearities in our original optimization problem, in the objective function as well as in the constraints, to consider. In general, one appears as soon as we must write a condition "if ... then ..." somewhere, cf the examples which come below.
In order to keep having a model whose formulation is linear, the trick is to introduce “dummy” variables so as to represent the possible output of those non-linear operations. In order to keep considering only consistent states of the original optimization problem, we need to define constraints to make it so that only the global states of the variables - where the respective values of those dummy variables are consistent with the values of the decision variables - are allowed. Once this is done, we can easily define the originally non-linear costs / constraints, as linear costs / constraints of those dummy variables.
Here is a non-exhaustive list of cases where such non-linearities can occur:
Case 1: Implementing conditional cost / gain components
Problem
The part \(G\) of the objective function considering the gains earned by the model must be such that the gain \(G_J\) associated to the completion of a job \(J\) must be taken into account if and only if the allocation state proposed by the model is such that the job can indeed by completed (if enough employees are being allocated during enough days to this job, basically).
\[ G = \sum_{J} \begin{cases} G_J & \text{if } J \text{ is completed} \\ 0 & \text{otherwise} \end{cases} \]
Solution
We create a dummy binary variable \(d_J\), and constraint it so that its value is equal to 1 if the condition is met, and 0 otherwise.
Then we use this dummy variable in the objective function:
\[G_J = \sum_{J} G_J \times d_J\]
In the case when \(d_J\) is supposed to represent the fact that a sum \(S_J\) of variables is positive or not (with \(d_J = 1 \Leftrightarrow S_J > 0\)), the dummy constraints needed to force the dummy variable to take consistent values can be written as:
- \(d_J \leq S_J \quad \quad \quad \quad \quad\) (to implement \(S_J = 0 \implies d_J = 0)\)
- \(M \times d_J \geq S_J \quad \quad \quad \quad\) (to implement \(S_J > 0 \implies dj = 1)\)
where \(M\) is a big positive value, which must be superior or equal to the maximum value that the sum \(S_J\) can take.
If the value of the dummy variable is not important if the sum is equal to 0 (e.g. if we just need that the \(S_J > 0 => d_J = 1\) relation be verified), then we can dispense with the first dummy constraint.
Case 2: Implementing conditional constraints
Problem
The maximum workload allowed on day \(D\) for a given employee \(E\) takes a specific value \(MW_1\) by default, but will take a slightly higher value \(MW_2\) if the number \(N_{D,E}\) of jobs to which the employee is allocated to during the day is equal to 1, in order to allow the possibility to do some kind of overtime in that circumstance.
\[ w_{D,E} \leq \begin{cases} MW_1 & \text{if } N_{D,E} > 1 \\ MW_2 & \text{otherwise} \end{cases} \]
where \(w_{D,E}\) is the total workload of the employee \(E\) on day \(D\).
Solution
We create a dummy binary variable \(d_{D,E}\), representing whether or not the employee is working on a single job on that day, and constrain it so that its value is equal to 1 if \(N_{D,E}\) is inferior or equal to 1, and 0 otherwise. Then we use this dummy variable in the definition of the constraint:
\[w_{D,E} \leq MW_1 + (MW_2 – MW_1) \times d_{D,E}\]
The dummy constraints to be implemented are the following:
- \(-M \times d_{D,E} \leq N_{D,E} - 2 \quad \quad \quad\)(to implement \(N_{D,E} \leq 1 \implies d_{D,E} = 1\))
- \((1 - d_{D,E}) \times M \geq N_{D,E} - 1 \quad\) (to implement \(N_{D,E} > 1 \implies d_{D,E} = 0\))
where \(M\) is a big positive value, which must notably be superior to the maximum value that \(N_{D,E}\) can take, as well as superior or equal to 2.
Case 3: Implementing conditional constraints in function of the value taken by a non-binary variable
Problem
We may need to consider a ternary variable \(X\), whose value can be either 0, 1 or 2, and we may need to implement different constraints on the problem, following whether its value is 0, 1 or 2. For instance, assuming we have a variable \(Var\) which must be constrained differently in function of the value of \(X\), with two positive threshold values \(T_1\) and \(T_2\)
\[Var \leq \begin{cases} 0 & \text{ if } X = 0 \\T_1 & \text{ if } X = 1\\ T_2 & \text{ if } X = 2 \end{cases} \]
then how can we go about it?
Solution
One way to manage this case is to build \(X\) as the sum of two binary variables \(X_1\) and \(X_2\), with adding the constraint \(X_2 \leq X_1\), as well as the other dummy constraints needed to make sure that both of them take the appropriate values at the appropriate time to adequately represent the original value of \(X\).
Then the initial constraint can be formulated as one by distinguishing in it the \(X_1\) part and the \(X_2\) part:
\[Var \leq T_1 \times (X_1 - X_2) + T_2 \times X_2\]
Case 4: Lightweight implementation of Max –based cost component using operational assumptions
Problem
We may need to implement the use of a Max or Min function at some point when computing the value of the objective function (ex: to represent a fixed cost, or a linear cost appearing only once a specific threshold is met). This can be thought of as a particular case of the notion of conditional cost:
\[ cost = C \times \text{max(} var - threshold ; 0 \text{)}) \\ \Leftrightarrow cost = C \times \begin{cases} var – threshold & \text{ if } var \geq threshold \\ 0 & \text{ otherwise} \end{cases} \]
Solution
In that case, we can create a dummy variable \(var_{\text{extra}}\) to represent the part of \(var\) which is above the value of \(threshold\), and use it in the objective function itself:
\[ var_{\text{extra}}= \begin{cases} var – threshold & \text{ if } var \geq threshold \\ 0 & \text{ otherwise} \end{cases} \]
\[cost = C \times var_{\text{extra}}\]
If there is an implicit constraint that the variable must be non-negative, then the dummy constraint to implement to support this dummy variables are the following:
- \(var_{\text{extra}} \geq var – threshold \)
- \(var_{\text{extra}} \leq var – threshold \text{ if } var \geq threshold \)
However, if we can make the assumption that the solver will want to minimize \(var_{\text{extra}}\) (because, for instance, this value is penalized in the objective function to minimize), then we only have to specify the lower bound constraint, instead of specifying both the lower bound and the higher bound constraints. Here, it means that we would only need to specify the \(var_{\text{extra}} \geq var – threshold \) constraint.
To note
When using CPLEX as the solver, and the ‘docplex’ python library as the API used to specify the optimization problem, it is possible to use functions such as ‘max’ when defining the objective function, or to implement conditional constraints. The API will define by itself the additional dummy variables and dummy constraints needed to do so. However, as presented in this Case 4, by relying on some assumptions, it is possible to not have to define some of those dummy constraints (and so, to reduce the number of constraints that the solver will have to deal with), so it can still be interesting to define the dummy variables and constraints ourselves.
Example
With the following problem:
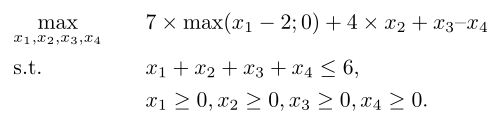
We see that in order to solve the problem, the engine will need to maximize \(x_1\), with a value superior or equal to 2. So we can deal with the ‘max’ function by creating \(x_{1,m}\) as a variable of the same type as \(x_1\), with the only additional constraint being \(x_{1,m} \leq x_1 - 2\), and then the objective function becomes \(7 \times x_{1,m} + 4 \times x_2 + x_3 – x_4\). The problem becomes
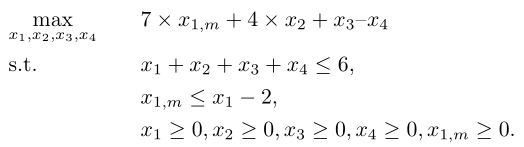
When performing the test, with the ‘docplex’ API, 5 dummy variables and 7 dummy constraints are needed, whereas only 1 dummy variable and 1 dummy constraint are needed, when using our assumption.
Bonus
An appreciated side effect of using dummy variables is to be able to keep the formulation of the optimization problem clear and easily understandable, as far as operational rules as concerned.
For instance, here, we may have cases where, \(N_J\),the number of employees to be allocated to a job \(J\), over all the necessary days, is specified in advance.
If we only have the original decision variables \(x_{J,D,E}\) to work with, for a given job, we can formulate this constraint by doing something like
\[ \sum_{E} \begin{cases} 1 \text{ if } \sum_{D} x_{J,D,E} > 0 \\ 0 \text{ otherwise} \end{cases} = N_J \]
, which can quickly make things unclear, regarding which operational constraint this is supposed to represent.
Whereas, once we have defined dummy binary variables \(y_{E,J}\) representing “employee E is allocated to job J”, we can implement those constraints just by writing \(\sum_{E} y_{J,E} = N_{J}\).
Containing the increase in the number of variables and constraints
However, as a result of using those tricks, the number of variables and constraints in the model can increase significantly.
In order to mitigate the effect of this on the complexity of the model, and on the duration needed to solve the optimization problem, we try, as much as possible, to apply constraints before even modeling the problem. That is to say, if we know that a decision variable corresponds to the allocation of an agent to a job on a certain day which will not be possible (due to availability or skill constraints, for ex.), then we do not bother creating the decision variable in the first place. That way, only remain the decision variables whose value is truly uncertain before solving the problem, and which will have to be dynamically tested.
Also, as described in the section above, it is also useful to define ourselves the dummy constraints, and to take advantage of the assumptions that the solver will consider proper default values for some dummy variables (because doing that helps it minimize the value of the objective function).
Dealing with route data
In order to consider whether an agent can be allocated to a job, and if they can be, which cost it would entail to do so, we need to have information about the means of transportation, duration and price associated to a travel of a given agent to a job’s location. Given the number of possible locations for both agents and jobs, this implies having access to travel info for a lot of (origin; destination) pairs, and for locations belonging to a lot of different countries.
In order to get access to such info, we combine the use of an internal database, built from the feedback gained from past allocations, and the use of external service providers, which may vary from one country to another (ex: Baidu’s API for routes between locations in China).
However, even with this, we may find ourselves encountering an (origin; location) pair for which we may lack the needed info at runtime. In order to deal with those case, and as a last resort, we train a simple machine learning model on the data that we already have, in order to get an estimate of what the travel info would be for an as-yet-unfetched (origin; destination) locations pair.
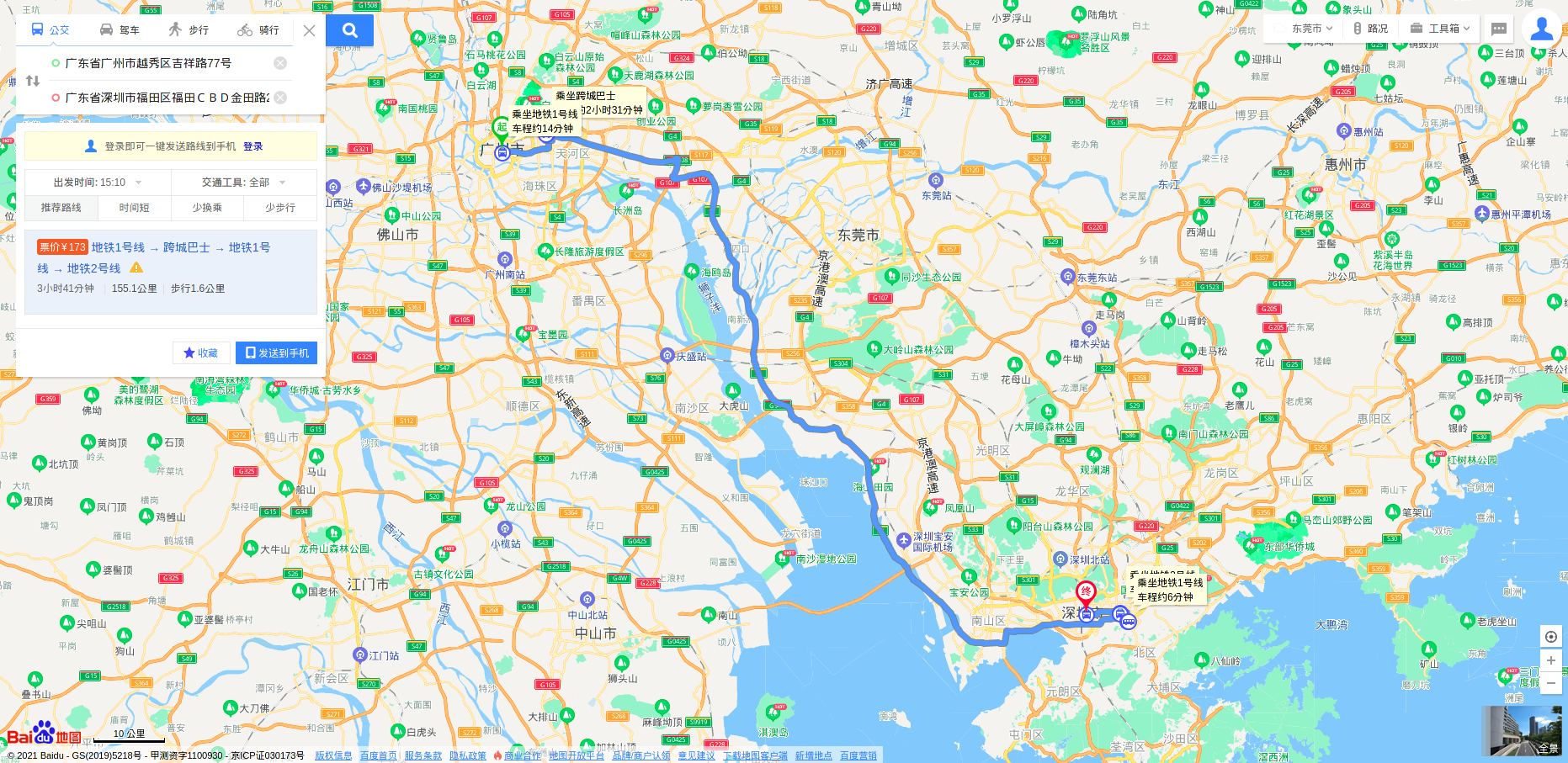
Dealing with location representation
In order to take travels information into account, we must first be able to represent locations, within the engine. In our project, we deal with location info by geocoding the position of an agent, or of a job, from the address info which are associated to them in our system. We need to consider an appropriate level of precision for the geocoding: we need to be precise enough so that the travel info queried from them will be relevant, and allow us to make the right considerations regarding agents’ possible allocations and travels costs; but too much geocoding precision is not necessary either (whether the job’s location is at n°X or n°Y of the street does not really matter), and can be in fact detrimental to us, since this increases the number of (origin; destination) pairs for which we would need to query travel info. As such, we try to geocode to a precision level up to a “district” in a “city”. We use the GoogleMap API to carry out the geocoding; and we store the fetched data in our internal database.
Dealing with combinational issues
We also have to deal with the possibility for an agent to be allocated to work on several jobs on a given day, if the jobs are shorts, and if their respective locations are close enough. That means that a priori we need to consider, for each inspector and each day, not only the jobs that they can be allocated to, but also the order in which they would tackle a subset of those jobs, as this would affect the travels to be performed, and as such, also, the jobs which are possible to be worked on later during a day.
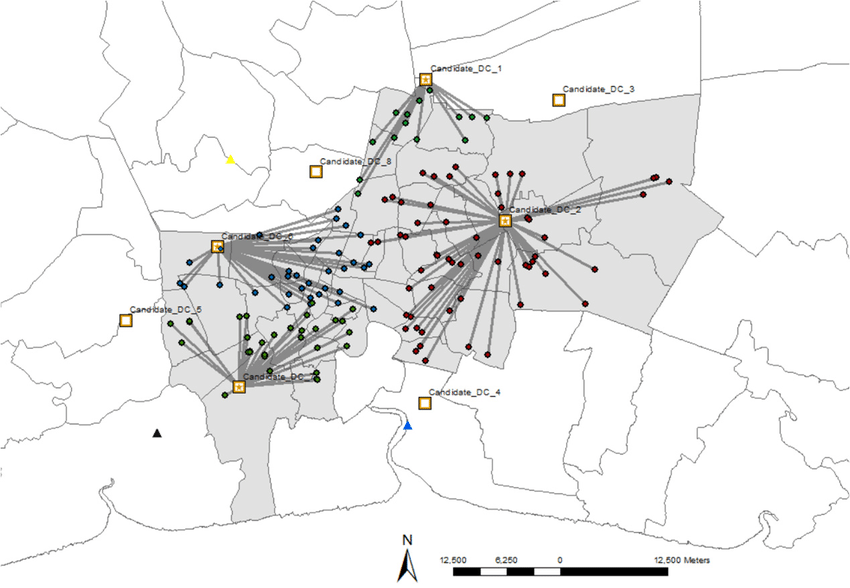
Doing this while keeping the linear structure of the model would entails a combinational explosion of the number of dummy variables and additional constraints to implement. Instead, we decided not to consider the order in which jobs would be carried out, and to do away with considering the specific travel between one possible job location and another. We decided to divide the territory over which the jobs are located into “geographical zones”, where the travel info to go from one job to another is approximated as the travel whose duration is longest. We then add to the model the constraint that an agent can go to only one geographical zone per day. Which means that, for a given day, once the geographical zone is set, the agent can be allocated only to jobs whose location is within this zone. Zones can overlap with one another.
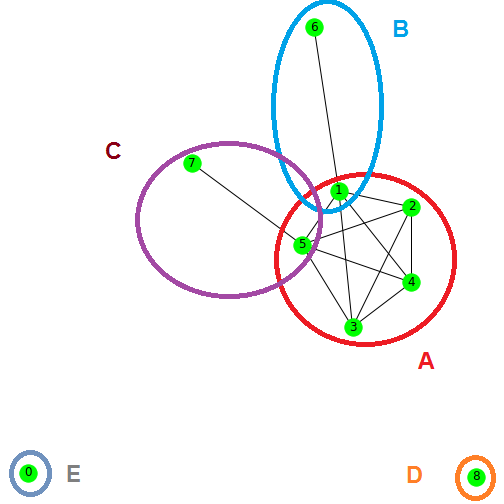
Here, in order to define the zones, we first considered the graph of jobs’ locations, where the nodes are the locations, and an edge exists between two nodes if the duration of the travel needed to go from one to the other (in both directions) is below a given threshold (ex: less than 40 minutes). We then define the geographical zones as the cliques of this graph - that is, the groups of nodes such that an edge exists between each pair of nodes within a given group (two edges if we consider the graph to be directed). Operationally, this guarantees us that every job’s location within a zone can be reached from another one in less that the amount of time used as the threshold value, which will have been chosen because deemed reasonable when having to perform more than one job during a day.
Finally, to account for the travels needed to perform all jobs that an agent has been allocated to, we take into account the duration of the travel needed to go to a geographical zone, when computing an inspector’s day workload, and not just the workload associated to tackling jobs.
Technical choices
After testing several solver solutions or service providers, we decided to use the Saas Decision Optimization service of IBM, notably for solving linear problems (based on CPLEX), which allows to send to IBM’s plateform the optimization problem as compressed data, and then just wait for the solving job to be completed. At the time when we began this project, the service was called DropSolve. It has since then been discontinued and replaced by IBM’s a specific use of Watson Machine Learning service. It is possible to use this service with a ‘pay as you go’ plan, which suits our current need rather well.
We programmed our allocation engine in python, which notably allows us to use the docplex library to define the optimization problem, as well as the specific ibm_watson_machine_learning library which exists in order to interact with IBM’s WML service’s API.
The use of IBM's WatsonML's service is not without some flaws, such as the fact that the 'ibm_watson_machine_learning' library is still pretty recent and might lack some useful functionalities (such as automatic retry when there are connection issues), the lack of documentation regarding the possible responses of the API to various queries (and in which ways those queries can fail), or the fact that there may be issues affecting the ability to use the service from time to time. But up until now the service v. price trade-off has still be positive for us.
Other solver solutions that have been considered, and may be potentially used in the future, include:
- CPLEX
The underlying software to IBM’s Watson ML service. We may want to use it directly, on premise, however right now the cost of the license needed to do that is too important for our use case, compared to the 'pay-as-you-go' use allowed by IBM's Watson ML. - Gurobi
Allows to get access to Saas solver solution, just like IBM’s Watson ML, performing better (faster problem resolution); we may be interested in switching to it if the optimization problem becomes really too complex / with too many constraints. - LocalSolver
A promise of good performances while being able to specify the optimization problem using non-linear operators directly, notably operators over sets. We need to first reformulate our optimization problem with their API's library before being able to test out their service.
Other solutions, which did not allow to perform Mixed Integer Linear Programming at the time, or whose performance level was too low to suit our need (the solving took too much time), include:
Aside from that, we use a local sqlite database in order to store temporary data and do computation with them, as well as persistent data, such as geolocation of addresses.
Finally, as we said, we use GoogleMaps for geocoding, as well as external services such Baidu for fetching info about travels.
Conclusion
Setting up this system to automate away part of the allocation task has been an interesting exercice in operational constraints framing and in achieving an adequate compromise in terms of performance v. costs, forcing us to get creative regarding the ways to define the optimization problem.
The allocation engine keeps being improved, with allocations rules being updated or revised as people are more and more integrating the interactions with the engine in their workflow. As far as the future of the implementation is concerned, as more and more operational rules are added, the performance v. cost trade-off might tip the balance in favor of one of the more powerful solver solutions referenced above. If we go this way, we may relax the use of some of the tricks used to linearize the model, which should in turn provide us with even more adequate suggestions.
However it will go, it will have been an interesting experience to linearize such an optimization model, to get the most of the more affordable existing solver solutions.
References
- Tricks for specifying non-linear operations when defining a linear optimization problem: https://agecon2.tamu.edu/people/faculty/mccarl-bruce/mccspr/new15.pdf
François Noyez – Data Scientist at Qima


