
In a previous blog post we have been through the design of a Public API that we developed at QIMA. Now we will explore our testing strategy for this multi-component system. We will specifically dig into the setup of integration tests in our Continuous Integration (CI) platform.
Prerequisites
- Basic knowledge of Git (branches, commit).
- Basic knowledge of docker / docker-compose.
- Basic understanding of what maven is.
What to test?
Let’s first have a look back at the architecture of the API built previously (feel free to refer to the previous blog post)
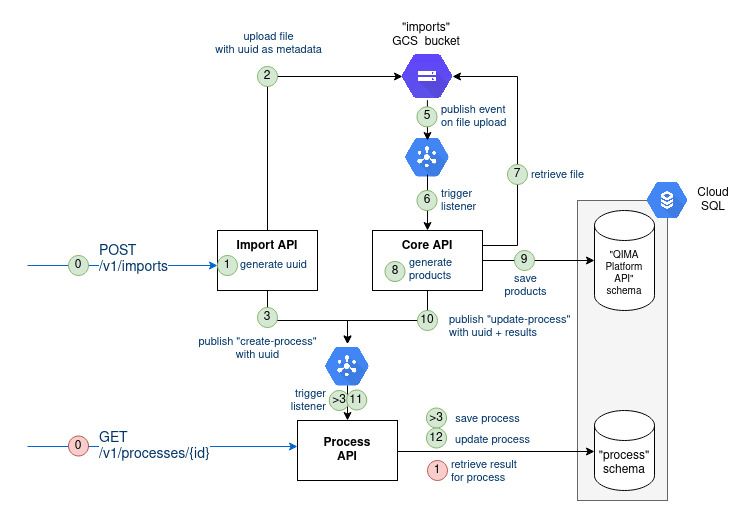
For our three homemade components (Import API, Core API, and Process API) we resorted to different types of tests:
- unit tests: white-box test the public method of our java class.
- Mock external class.
- Very easy to setup/write, very fast to execute.
- We wrote a lot of them to reach our test-coverage standards. - component tests: black-box test one single component.
- Run/emulate external services.
- Not so easy to setup/write, long to execute (starting the component takes a while).
- We wrote a few of some of them to cover the most important business cases.
This testing is essential, but not sufficient. Back to figure 1, you can notice that information flows between the three components and through some Google Cloud services (Storage, Cloud SQL, PubSub). We would like to test the proper integration of all those pieces together.
Hence the need for integration tests: black-box test all the components together.
- Run/emulate external services.
- Hard to setup/write, long to execute.
- There are only a few ways messages can flow between the components hence very few tests cases are needed at this level of testing. The two aforementioned types of tests types should have anyway already tested the functional behavior of each component.
We have followed the Pyramid strategy for tests:
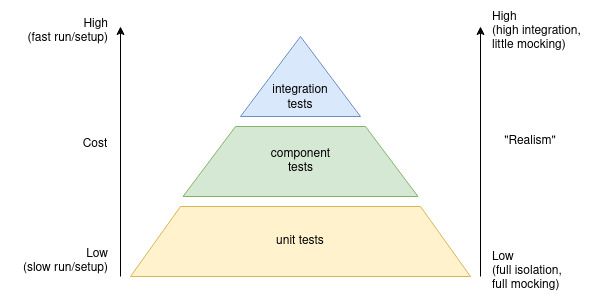
Note that we are only considering the tests written by developers and not those written by Quality Assurance (QA) engineers. The goal is to prevent any regression from being merged onto the main branch.
We will only focus on integration tests as they are the most challenging to setup locally and in CI.
Implementation
Testing the system locally
Our ultimate goal is to have integration tests working in our CI platform. But first, let’s try to have these tests work our a local machine. It will reduce the feedback loop which can be long when interacting with remote machines of the CI.
[locally] Emulate external services
As a reminder, our API is made of 3 “internal/homemade” components:
- Public API: responsible for ingesting the data of the customer
- Core API: responsible for processing the data of the customer
- Process API: responsible for exposing the ingestion/processing results to the customer
Those “internal” components depend on 3 “technical” services:
- PostgreSQL: the relational database to persist the long-lived data
- Google File Storage: the file storage to save binary files
- Google Cloud PubSub: the message broker to send/receive message between components
We will run an actual PostgreSQL instance.
We will emulate the File Storage (using MinIO OpenSource tool).
We will emulate the message broker (using pubsub-emulator, the official Google Cloud PubSub emulator)
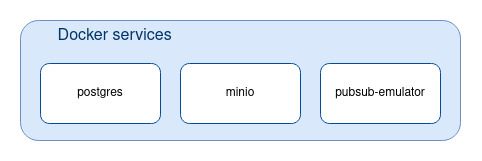
We use docker to run those 3 services.
The services are defined in the docker-compose.yml:
# docker-compose.yml
version: '3.6'
...
services:
postgres:
image: postgres:X.Y.Z-alpine
environment:
- POSTGRES_DB=...
- POSTGRES_USER=...
- POSTGRES_PASSWORD=...
- POSTGRES_HOST_AUTH_METHOD=...
volumes:
- pgsql-data:/var/lib/postgresql/data
- ./backend/docker/pgsql_scripts:/docker-entrypoint-initdb.d
# /backend/docker/pgsql_scripts folder contains one init.sql script
# that creates schemas users and grants permissions.
ports:
- 5432:5432
...
pubsub:
build: compose/pubsub
ports:
- 8085:8085
...
minio:
image: minio/minio:RELEASE-XXX
environment:
- MINIO_ACCESS_KEY=...
- MINIO_SECRET_KEY=...
- MINIO_DOMAIN=importbucket.minio,importbucket.localhost
volumes:
- minio-root:/root/.minio
command: server /build-data
networks:
default:
aliases:
- importbucket.minio
ports:
- 9999:9000
...Here is how the services can be started:
# To be run in the same folder as the docker-compose.yml
docker-compose up postgres
docker-compose up pubsub
docker-compose up minioWe now have our external dependency services up and running:
[locally] Prepare the database for the tests
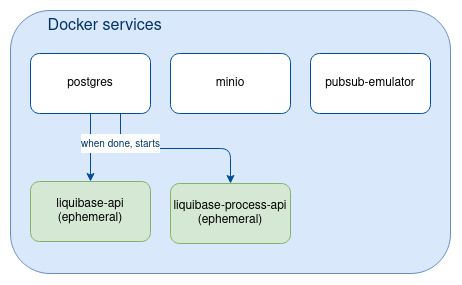
The “Core API” component uses liquibase to run database migration (create/alter/delete tables) and to inject test data in database. liquibase-api is executed as a docker service in the docker-compose.yml:
services:
...
liquibase-api:
image: qima/api:latest
depends_on:
- postgres
environment:
- DATABASE_URL=jdbc:postgresql://postgres:5432/${DATABASE_NAME}?currentSchema=qimaone
- DATABASE_USERNAME=XXX
- DATABASE_PASSWORD=XXX
command:
- ash
- -c
- |
java [some custom args...] update
...liquibase-api can be run with the following comand:
docker-compose up liquibase-apiThe “Processes API” also resorts to liquibase to setup the database.
Likewise we will define a liquibase-processes service inside the docker-compose.yml, and start it as such:
docker-compose up liquibase-processesThe lifecycle of those liquibase-XXX docker-compose services differ from postgres, minio, pubsub as they will be stopped once completed (ephemeral services).
Note: “Public API” component does not need liquibase since it does not interact with the database.
[locally] Start internal components
Once the external dependencies (Postgres, Minio, PubSub) are up and that the database data is ready, we can run our three internal components (“Core API”, “Public API”, “Proceses API”) .
Those three Spring Boot apps can be run with the following Maven command:
# Core API listening on localhost:8080
mvn spring-boot:start --projects api --also-make -DskipTests
# Public API listening on localhost:8090
mvn spring-boot:start --projects public-api --also-make -DskipTests
# Processes API listening on localhost:8091
mvn spring-boot:start --projects processes-api --also-make -DskipTestsHere we are: the application is fully running locally and we can now perform some testing on it. Still, note that the three java apps do not run within docker (for now…).
[locally] Implement the integration tests
Our three components are part of the same multi-module maven project (one maven module per component). We decided to create a new maven module named “integration-test” where we would write our java tests. This module does not contain anything else but tests (no “main” package).
What should be tested? As explained earlier, each individual component of the system has already been tested by both unit and component tests. Our integration tests should above all ensure the proper flow of information across components, which has not been tested yet.
Our import API supports 3 types of business objects:
- products
- purchase orders
- measurements.
For each of them we want to validate 2 scenarios:
- 1 scenario for the well formatted import file
- 1 scenario for the badly formatted import file
Hence we will write 3 x 2 = 6 tests scenarios in total.
Here is a high level description of our tests scenarios for the products:
- POST the CSV file on http://localhost:8080/api/v1/imports/products and get back the processId.
- Repeatedly GET http://localhost:8091/api/v1/processes/{processId}, until we get the expected success/failure. Save the ids of the product.
- In case of success, for each product GET http://localhost:8090/api/products/{productId} and check it exists.
The same will be done for both purchase orders and measurements.
Apologize, no fancy code to showcase...
And here is the maven command to run the tests locally:
# To be run the root of the multi-module maven project
mvn verify --projects integration-test --also-makeAll the tests are green? Yes? Let’s proceed!
[locally] Dockerify the whole app
Now let’s include our three components in the docker-compose that hosts external services.
First let's build the docker images of our three components. Here are the image names:
qima/apiqima/public-apiqima/processes-api
Let’s reference those docker images from our docker-compose.yml and define three new services:
# docker-compose.yml
services:
...
api:
image: qima/api:latest
command:
- ash
- -c
- |
# Run the API
java [many more arguments...]
public-api:
image: qima/public-api:latest
command:
- ash
- -c
- |
# Run the Public API
java [many more arguments...]
processes-api:
image: qima/processes-api:latest
command:
- ash
- -c
- |
# Run the Processes API
java [many more arguments...]
Here is how we can start those three services:
docker-compose up api
docker-compose up public-api
docker-compose up apiAnd here is the final state of the services defined in our docker compose:
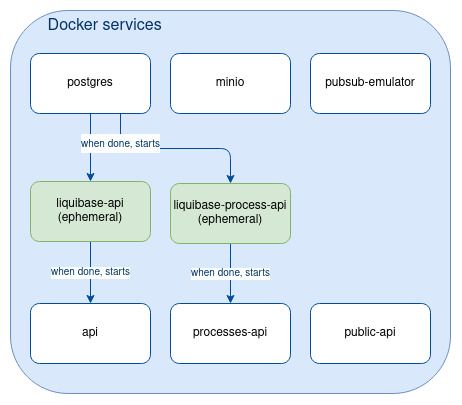
[locally] Manage inter-service synchronization
Let's recap the steps needed to start the whole stack and run the integration tests:
- Run:
# In any order
docker-compose up minio
docker-compose up pubsub
docker-compose up postgres2. Wait for those docker-services to be ready…
3. Run:
# In any order
docker-compose up liquibase-api
docker-compose up liquibase-processes 4. Wait for those docker-services to be executed…
5. Run:
# In any order
docker-compose up api
docker-compose up public-api
docker-compose up api6. Wait for those three services to be ready…
7. Run:
mvn verify –pl integration-test –am8. wait for the tests to execute…
As you can notice, most steps consist of “waiting”. This is due to inter-dependencies between services. We should be able to automate it so that the whole stack is triggered in a single docker command (step 1 → step 5).
To understand better the dependencies, let’s model all our components as a Direct Acyclic Graph (DAG) (arrow = right-side component depends on completion/readiness of the left-side component):
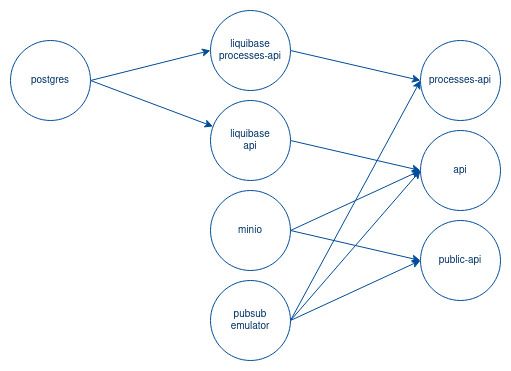
Let’s implement this dependency model in our docker compose.
Docker compose provides a depends_on keyword to specify dependency from one service to another. The issue is that docker assumes that a dependency is fulfilled once the service has started up (default behavior). In some cases, even though the docker service has started the app is not ready yet (e.g. “api” service), or the docker service has started but it still needs to execute some tasks (e.g. “liquibase-api” service). We must find a mechanism to enforce those logical dependencies.
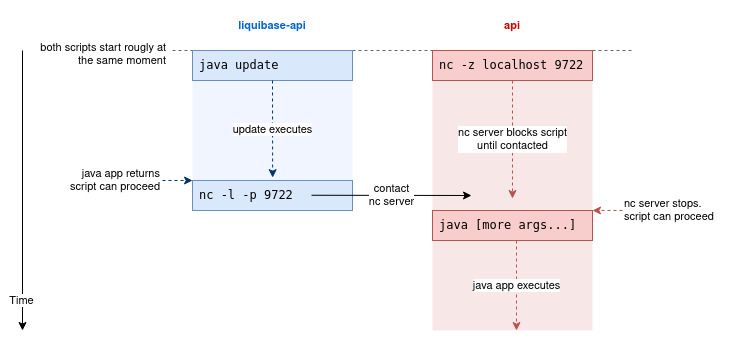
Here two Unix commands to block a bash script:
nc -z "$HOST" "$PORT": will run a server listening on given host:port and block the current script until the server is not contacted. Once the server is contacted, the server stops and the script proceeds.nc -l -p "$PORT": will contact the server on http://localhost for the given port and block the current script until no server responds. Once the target server responds, the script proceeds.
Let’s take a simple example. The api docker service requires liquibase-api docker service to be completed before starting. Here is how we can ensure the inter-service synchronization through scripting:
...
services:
liquibase-api:
...
depends_on:
- postgres
command:
- ash
- -c
- |
# Run the Liquibase
java update
# Liquibase update successfully completed at this point!
# Unblock the api (NB: script will be locked at this line as long as the target server is idle)
nc -l -p 9722
api:
...
depends_on:
- liquibase-api
command:
- ash
- -c
- |
# Block until the server on 9722 is contacted (...by liquibase-api service)
nc -z localhost 9722
# Run the API
java [many more arguments...]With nc command we can now ensure the proper ordering of the two java commands.
We use the same mechanism to enforce all the logical dependencies modelled on the DAG (Figure 6).
One single command is now required to start the whole stack locally:
docker-compose upRunning the tests in the CI pipeline
Now that we are able to run integration tests locally, it is time to run them in our CI pipeline.
For now each of our Github pull request (PR) triggers the following actions in our CI:
- checkout code (from Github)
- build
- run tests
- build/tag docker images
- push docker images (into Google Cloud Storage)
- update Kubernetes apps descriptors to trigger the continuous delivery workflow (ArgoCD)
We will tune steps 2, 3, 4 to add our integration tests.
[CI] CircleCI wordings and definitions
We use CircleCI as our CI platform.
The building block of each CircleCI project is a “pipeline”. The pipeline of a project (and all its recursive children) is configured through a config.yml file. Each pipeline contains one or more workflows.
A “workflow” is a DAG of one or more jobs.
A “job” is an isolated unit of computation that can execute script to perform any kind of action (Checkout code from Github, Build docker image, Run Tests, Push docker image on a registry, etc.).
A “workspace” is a shareable storage. It can be used to pass binaries between jobs.
In case at least one job fails to execute, the workflow is marked as “failed”, and so is the pipeline. A failed pipeline for a PR will prevent code from being merged onto the main branch.
[CI] Adapt our CircleCI workflow
Here is the CircleCI visualization of our existing worfklow (DAG from left to right, each rectangle is a job, let’s not consider blurry jobs):
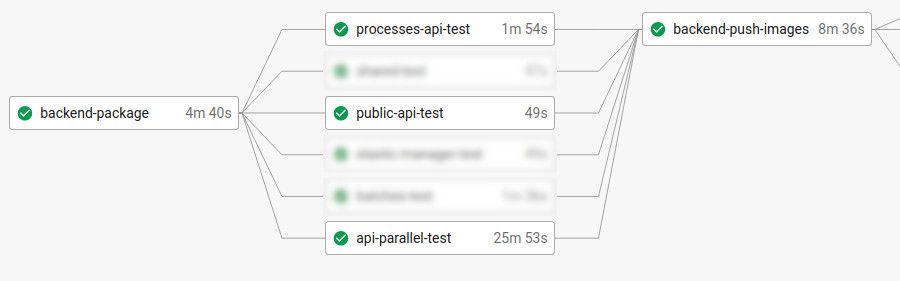
Here are the main steps for each of those five jobs:
- backend-package
- checkout git code
- build from code to binary (download maven dependencies, compile)
- store the binary in a CircleCI shared workspace (to be reused by downstream jobs) - api-test & public-api-test & processes-api-test
- download the binary from workspace
- run the tests against the binary - backend-push-images
- build/tag the docker image from the binary
- push docker images on a Google Cloud Storage bucket
Let’s adapt this workflow to run our integration tests.
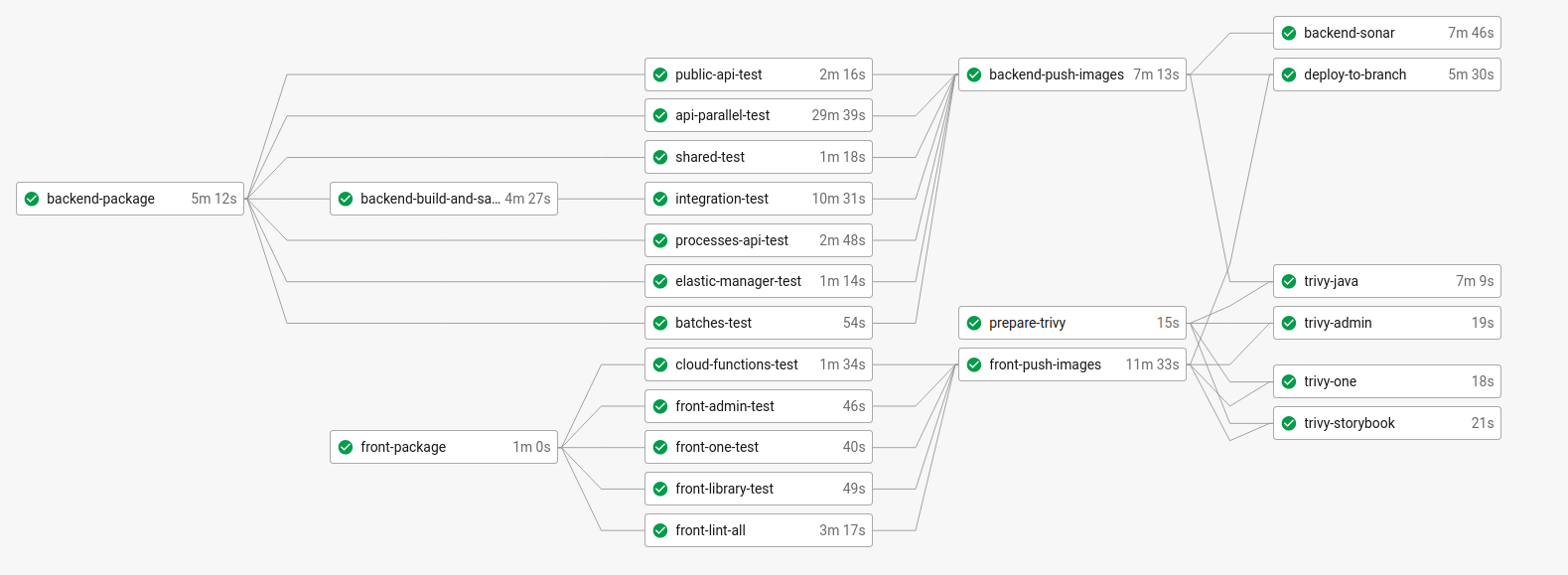
First we create a new job integration-test. This job will:
- build the docker images of our three homemade components.
- start the whole stack with docker-compose.
- wait for the whole stack to have started up… (we will tackle this point later).
- run the integration tests.
One drawback of this approach is our step 1 builds the docker images which are also built once again in backend-push-images. This can be time-consuming and we’d better find a way to have it done only once.
Then, let’s create create a new job backend-build-and-save-images which will:
- build the docker images
- share docker images for later use by downstream jobs
integration-testandbackend-push-images(which we renamed as it does not build anymore).
The issue is that there is no such thing as a shared docker registry between CircleCI jobs: if one job builds and tags a docker image, it will not be accessible from other jobs. The way to solve it is by passing docker images as binaries between jobs through CircleCI workspaces. Once a binary is uploaded in the workspace, downstream jobs can download it. Once the downstream job has downloaded the docker image as a binary, it needs to load it to its local docker registry.
Hereafter is a how we can set it up.
- Upstream job:
# inside ./circleci/config.yml
jobs:
...
backend-build-and-save-images:
steps:
...
- run:
name: Build docker image
command: docker build -t qima/api:latest .
- run:
name: Persist docker image to storage
command: docker image save -o /tmp/api.tar qima/api:latest
- persist_to_workspace:
root: /tmp/shared-storage
paths:
- '*'
...- Downstream jobs(s):
# inside ./circleci/config.yml
jobs:
...
integration-test:
description: 'Run the e2e tests on public-api, api, processes-api'
steps:
- attach_workspace:
at: /tmp/shared-storage
- run:
name: Load docker images
command: docker load -i /tmp/shared-storage/docker-images/api.tar
...
# Later step: start the docker-compose...
# Event later step: run the tests...
...So here is a view of our final CircleCI workflow:
[CI] Choosing the right executor
What we forgot to mention is that if one tries to execute the new CircleCI workflow in the way it was described, the tests should fail.
The reason is that CircleCI jobs execute on a docker executor by default. To avoid running a docker-compose inside a docker executor (docker inside docker) CircleCI simply runs the wrapped docker within a remote docker host (see CircleCI setup_remote_docker keyword): the docker-compose executes on a remote docker host. This leads to some issues:
- No shared network: the job docker executor and the remote docker are on different networks, hence the web client invoked in our integration tests is not able to reach the components running on the remote docker-compose.
- No shared volume: the remote docker cannot be be mounted volumes from the job storage. Hence there is no easy way to pass the database initialization script file to the docker-compose.
- Poor performance: it took around 30 mins to start the whole stack with a 8GB docker executor, while we expect a couple of minutes.
We can overcome those issues by executing the integration-test job on one of the virtual machines provided by CircleCI. We opted for a ubuntu machine:
# ./circleci/config.yml
...
jobs:
...
integration-test:
description: 'Run the e2e tests on public-api, api, processes-api'
machine:
image: ubuntu-2004:202104-01
resource_class: xlarge
steps:
...
...With this new configuration, the docker-compose directly on the executor machine.
[CI] Waiting for startup
Let’s tackle one last issue: when should the app be considered as ready? i.e. when should the tests be run?
To know whether a component is ready, we can resort to the “healthcheck” endpoints that we have implemented on our components: http://localhost:${COMPONENT_PORT}/actuator/health. Once a given component is ready, its “healthcheck” endpoint will be returning 200. By repeatedly calling each of them we can determine when the app is ready to be tested.
Our script will wait for all the components health checks to be ready before executing the tests.
Here is how this can be achieved:
# ./circleci/config.yml
...
jobs:
...
integration-test:
...
steps:
...
- run:
name: Wait for the 3 API components to be started
working_directory: /tmp/shared-storage/repo
command: |
set -xe
wait_for_readiness() {
local SERVICE="$1"
local PORT="$2"
local TRY_TIMEOUT=300
local TRY_INTERVAL=1
local REMAINING_TIME=$TRY_TIMEOUT
while ! curl http://localhost:${PORT}/actuator/health -s -I | head -n1 | grep -q 200;
do
REMAINING_TIME=$((REMAINING_TIME-TRY_INTERVAL))
if [ $REMAINING_TIME -lt 0 ];
then
echo "Error: '${SERVICE}' did not start in expected duration."
exit 1
fi
echo "Waiting for '${SERVICE}' to start... remaning ${REMAINING_TIME} seconds."
sleep $TRY_INTERVAL
done
echo "The '${SERVICE}' is ready to be tested."
}
wait_for_readiness 'api' 8080
wait_for_readiness 'public-api' 8090
wait_for_readiness 'processes-api' 8091
- run:
name: Run Cucumber Tests
command: |
set -xe
./mvnw verify --projects integration-test --also-make
...This solution is fine but presents some drawbacks:
- Long startup time can lead to test failure: tests will fail in case of slow startup of the app (beyond the 300 seconds
TIMEOUT) - No fail-fast: in case an error occurs while starting up the whole stack, it will only be noticed when the
TIMEOUTis reached.
Anyway, once all tests are green, we are confident to merge!
Conclusion
The main benefit of running integration test on the CI is clear: catch defects before merging on the main branch, in an automated way.
Yet, this approach is not straightforward and it’s worth considering some limitations we have already come across:
- Non production-like tests: the emulated cloud services (file storage, message broker) are not production-like. Their behavior might differ from real environment services. For instance our file storage emulator (minio) cannot trigger event as Google Cloud Storage does and we had to trick our tests to manually publish the corresponding event onto the message broker. Those tests do not give 100% guarantee about the API behavior on a real environment. More “realistic” tests ought to be performed on staging environments.
- Ever increasing tests duration and timeouts: the tests wait for the whole stack to be started before starting to test. As the app grows, the initial data needed for the tests grows as well. This leads to an increase of the startup time, which leads to an increase of the overall tests duration, sometimes beyond the timeout which then needs to be increased, etc.
- Painful debugging: in case of failure of integration tests, the error messages can be too light to understand what happened. This is because the tests are fully black-boxed into their docker environment. In order to get more information, the developer should connect onto the corresponding CircleCI job through SSH. This can be tedious and time-consuming. Some solutions could be implemented:
—> manually output the applications stack traces onto CircleCI (to have them displayed directly on Circle UI).
—> connect docker container logs onto CircleCI (here also to have them displayed directly on Circle UI).
Finally, let's consider the next step: run integrations tests on production-like environments. This will enable more realistic tests, with hopefully lower execution time, and provide developers with an easier way to investigate tests errors. The technical complexity of this step is high though and it should be weighed against the possible benefits of this new approach.
Written by Lois Facchetti, Software Engineer at QIMA


