
The project context
Business overview
QIMA is a leader in supply chain inspections for softline and hardline products. It is mandated by goods brands to inspect the quality of the products going out of their supplying factories.
QIMAone is a collaborative SaaS platform developed at QIMA. To make it simple, it enables brand managers to organize inspections for products, and inspectors to perform on-site inspections on those products.
Technical stack
QIMAone web application is made of a responsive Angular front-end, a Spring boot back-end, backed by a PostgreSQL database.
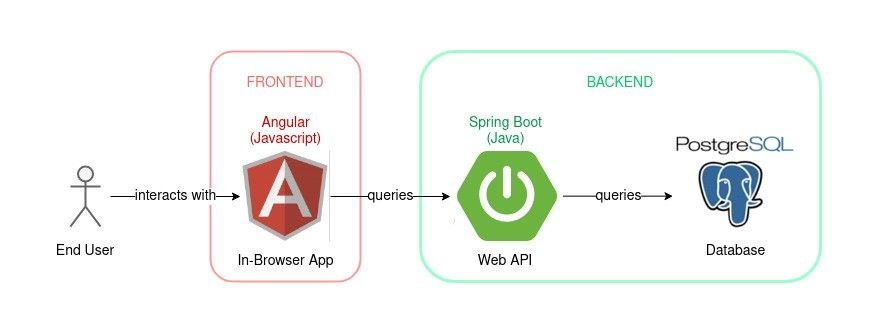
The app is deployed in Kubernetes on Google Cloud Platform (GCP).
The app utilizes various GCP services: Pubsub, Cloud Storage, Cloud SQL.
The Business need
Existing feature: import data via the UI
Brand managers need to create some data on the SaaS platform. As an example, they should register the products to be inspected. Each item can be created one by one with the UI, but this turns out to be time-consuming for large data sets.
To make this data creation more effective, QIMAone provides an “Import Feature” that enables the customers to import multiple products at once. To do so, the user should upload a structured CSV file that describes the data to be imported. Below is a simplified example of such CSV files describing 2 products:
Name | Reference | Description |
|---|---|---|
Glass - Model A | GLASSA | Transparent glass, volume 15cl |
Glass - Model B | GLASSB | Transparent glass, volume 30cl |
... | ... | ... |
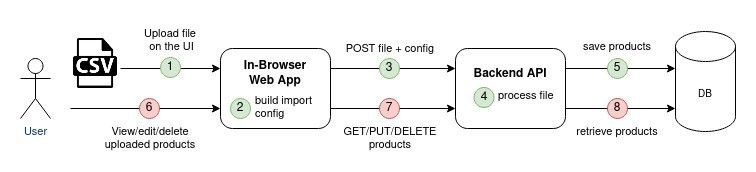
Current limitations
The “Import Feature” was working OK, but some limitations made it hard for the customers to adopt it:
- a user must manually interact with the UI of QIMAone. Customers would prefer scripts to perform the operation regularly and automatically.
- the user must remain connected to the app during the whole file processing. This processing can take a while and might therefore lead to timeouts. Besides, if an error occurs while processing the file, the user will have to perform the whole import again... until it works.
- In case of partial failure, the user has no accurate report of the import operation: which data could be successfully imported? Which data failed to be imported?
Functional requirements
- Expose a Public API to ingest new data on the platform.
- Enable users to log on the Public API with the same credentials as on Web App.
- Ensure coherency between the existing Web App Imports and the new Public API Imports: the same input file should produce the same data on the platform.
- Ensure backward compatibility of the solution: it should not change the way client use the Web App Imports.
Technical requirements
- High availability of the file upload.
- The file should be processed in a matter of hours.
- The system should be able to ingest files with 10k+ lines.
Disclaimer: those technical requirements lack formal metrics. The reason for this is that the business is still growing and accurate metrics would not make sense in such an unstable context where reaction rather than over-anticipation is the norm. Anyway, these requirements will drive our design.
Designing the new solution
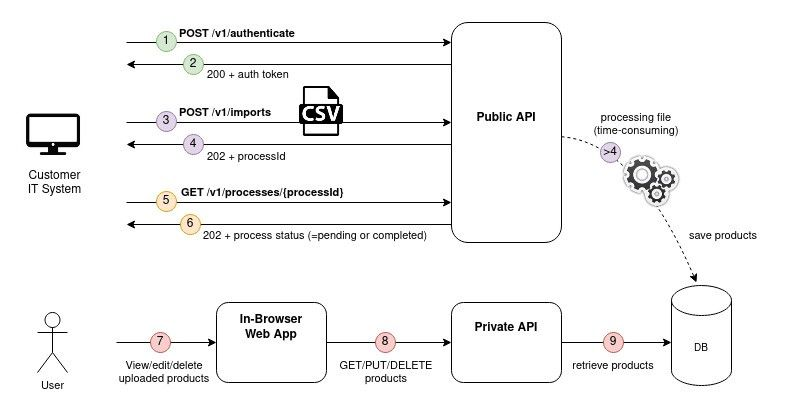
API specification
The new Public API will expose 3 endpoints:
- POST /v1/authenticate
Request body: {credentials}
Response: The JWT token that should be passed on the other endpoints to authenticate. - POST /v1/imports
Request body: {binary file}. A CSV structured file which describes the data to import.
Response: the id of the asynchronous process. - GET /v1/processes/{processId}
Response: the status of the asynchronous process: PENDING or COMPLETED.
If COMPLETED, provide a detailed report of successes/errors.
Note: this specification has been written as an OpenAPI Specification and is shared with clients who want to exchange with the Public API.
The notable change comes from the asynchronicity of the file processing. Note that this makes the user flow slightly more complex as it adds extra endpoint to retrieve the process status.
Step-by-step design
Now that we have our API specification done, we will iteratively make our system design evolve to reach the requirements.
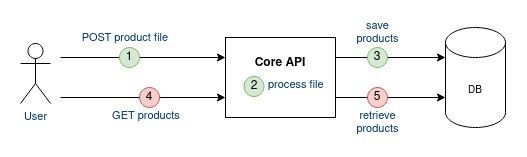
Let’s turn asynchronous
The first requirement to implement is to decouple the file upload from the file processing. To do so, the user will post the file on the Core API (1) that will store this file "somewhere” (2) and later on the application will retrieve (3) the file for processing (4). The conventional way to upload files on GCP is via Google Cloud Storage (GCS).
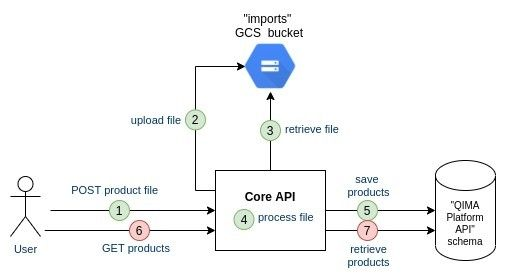
Pros/Cons:
[+] Shorter interaction time of the user with the API
[+] Lower failure risk in the user interaction with the API
[+] Technical decoupling between the file upload and the file processing: replay capabilities if the processing fails, better scaling/distribution capabilities for the future.
[-] Increase the complexity of the infrastructure and application logic
[-] Higher processing duration between the client upload and the import
[-] Harder local development with new component (GCS emulator) - but was already the case for other features
Move the Public API outside the existing API
For now a single component (Core API) entails the file upload and the file processing.
Let's extract the Public API components outside the Core API components to have better control on the deployment of the Public API to conform with High-Availability requirements and clear boundaries between our public/private components.
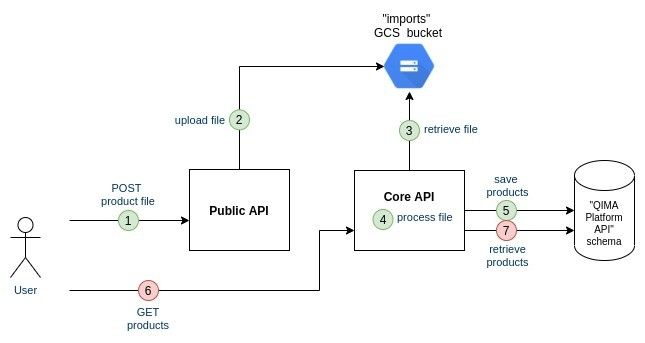
Pros/Cons:
[+] Decouple deployments of the Public API and the existing API
[+] Clear code boundaries between public and private components
[-] Less code cohesion between components which support the same feature
[-] Increase complexity of the deployment
[-] Harden local development (require to start 2 different apps to test the feature)
Extract /processes endpoint
Now let’s consider the /processes endpoint:
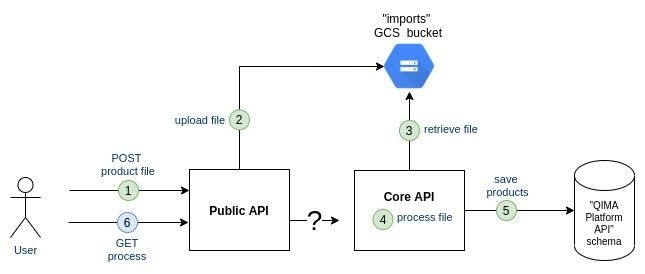
/processes endpoint is a purely technical component and the team estimated it worth extracting outside the Public API component. This new component named "Process API" will be re-used by internal batches to share their completion status. Process API component is a stateful component. To persist its state, we will create a new schema "process” in the existing database.
Here is the component split: Public API => Import API + Process API
Both Import API and Core API will share the status of the file processing to the Process API which will persist it in database. Later on, Processes API will retrieve and return the status when asked for it.
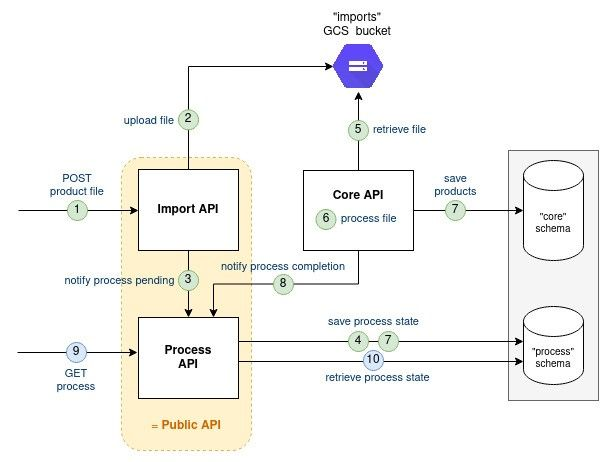
Pros/Cons:
[+] Reusable technical component “Process API”. We believe this is not too early a decision
[+] One-way information flow (no cycle)
[+] Isolated independent database schemas
[+] No cascading failure and no circuit breaker to implement “process” feature
[-] Harder local development due to the new component
[-] Increase database management complexity due to the new schema
[-] Increase deployment complexity due to new component
Communication from Import API to Core API
At this stage, the Import API has uploaded the file onto the storage. Now we should find a solution to notify the Core API to download and process the file.
Google Cloud Storage support an interesting feature: the Triggers. Those can be setup so that they are fired on each new file upload on a bucket. Those can then be published as messages on a dedicated GCP PubSub. Now if Core API listens to this PubSub, it can then read the message - which contains the file location -, download the file, and eventually process the file.
One last thing: the file content is not sufficient for the Core API to process it. Extra information needs to be passed (company ID, user ID, process ID). With Google Cloud Storage one can link “metadata” to a file. Let's use it then: the Import API will fill this metdata at the time of uploading the file on GCS. The Core API will then read the metadata from the Trigger event message, and be ready to process the file.
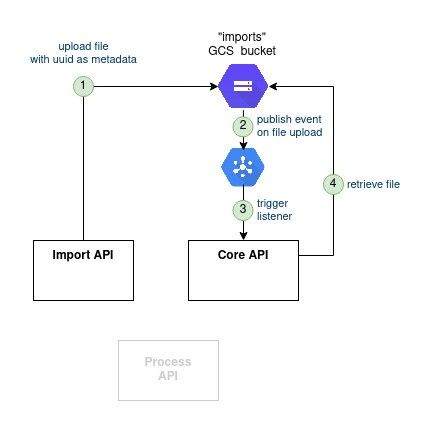
Pros/Cons:
[+] Async message queue communication: replay mechanisms, decouple failure, …
[+] Single/simple communication channel: Import API => Storage => Queue => Core API
[+] Little application logic involved in communication
[-] Increase infrastructure complexity
[-] The communication flow is distributed which makes it harder to debug on production
[-] Harder local development with new components - but were already present
Communication from Import API to Process API
When a user uploads a file on /imports endpoint, he receives a processID. With this processID, the user can query the /process/{processID}. Hence the processID needs to be shared between Import API and Process API.
Let’s determine how this processID should flow.
Option 1: synchronous communication between Import API and Process API
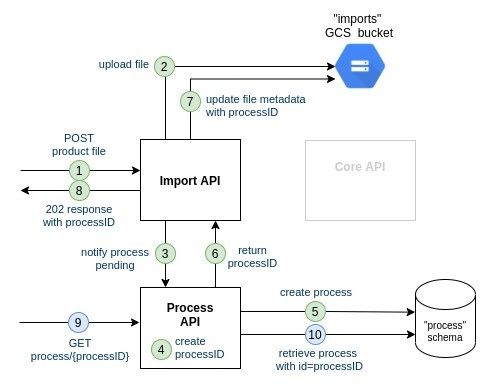
- The customer uploads a file on the Import API
- the Import API uploads the file on the file storage
- the Import API synchronously calls the Process API to notify that a new file has been successfully uploaded
- the Process API generates a new processID
- the Process API saves the process with id=processID
- the Process API returns processID to the Import API
- the Import API adds processID to the previsously-uploaded file metadata
- the Import API responds to the HTTP call with status 202 (Accepted) and with the processID in the response
- the customer reuses the processID just returned by Import API and queries Process API
The main issue with this synchronous approach is the cascading failure that can happen: in case Process API is down, the Import API is not able to respond with the process ID.
Option 2: asynchronous communication between Import API and Process API
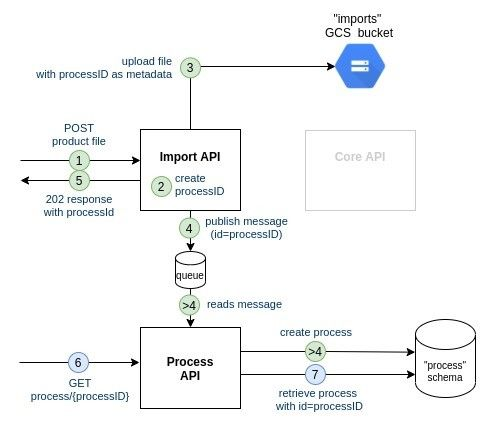
- The customer uploads a file on the Import API
- the Import API generates the processID
- the Import API uploads the file on file storage with the processID in metadata
- the Import API notifies asynchronously on a message queue that a file has been successfully uploaded, with the corresponding process ID
>4. (no guarantee about when this will occur) the Process API reads the message on the message queue, creates the process with id=processID - the Import API returns 202 to the customer alongside the process ID
- the customer reuses the processID just returned by Import API and queries Process API
To increase the availability of the Import API we choose to go for the asynchronous communication (Option 2). We will use GCP Pubsub as the queuing system:
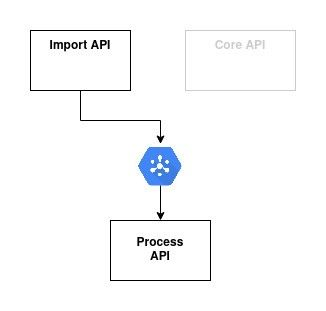
Pros/Cons:
[+] Strong message delivery guarantee
[+] No cascading failure nor need to implement circuit-breaker
[-] No strong consistency: once the user receives the process ID from Import API response, there is no guarantee that this process will be already created on the Process API)
[-] Lower code cohesion on application logic: the caller has the responsibility to generate the IDs
Communication from Core API to Process API
The Core API should communicate the status of the processing to the Process API. Likewise we can use a GCP Pubsub. Let's even re-use the same subscription as the ne Import API:
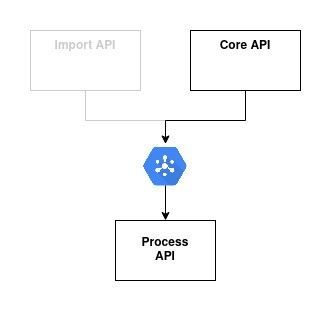
Two communication channels flow to Process API, and we should then be cautions about message ordering:
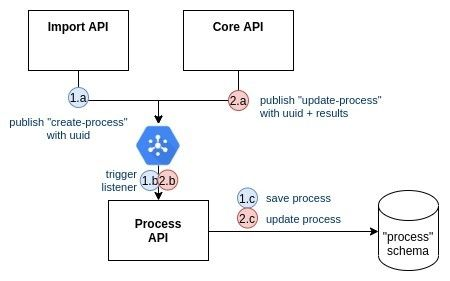
from Import API:
- Import API → Pubsub
- Pubsub → Process API
- Process API creates a PENDING process in DB
from Core API:
- Core API → Pubsub
- Pubsub → Process API
- Pubsub updates a COMPLETED process in DB
The only guarantees we have about ordering in this asynchronous system is:
- t(1.a) < t(1.b) < t(1.c)
- t(2.a) < t(2.b) < t(2.c) …with t(X) the time when X occurs
Nothing prevents the system from having t(2.c) < t(1.c): the COMPLETED operation could happen before the PENDING operation.
One way to solve this is by enforcing those two rules in the database transactions:
- when 2.c. occurs, write the data in database.
- when 1.c. occurs, only write the data if the process has not yet been inserted.
Pros/Cons:
[+] Strong message delivery guarantee
[+] No infrastructure overhead - it is already set
[-] Implement custom logic to handle ordering problem
Networking between the components
The Public API will be hosted on its own subdomain: api.qimaone.com (while the regular QIMAone platform is hosted on qimaone.com).
It was decided that the Core API component would be responsible to validate the user credentials and to forge the JWT token. All the components could validate the JWT token.
The API Gateway (Kong) will be in charge of redirecting the traffic to the right components. Here are the rules to enforce on the traffic:
qimaone.com/api/* → Core API
api.qimaone.com/v1/authenticate → [-“/v1” +“/api”] → Core API
api.qimaone.com/v1/imports → Import API
api.qimaone.com/v1/processes → Process API
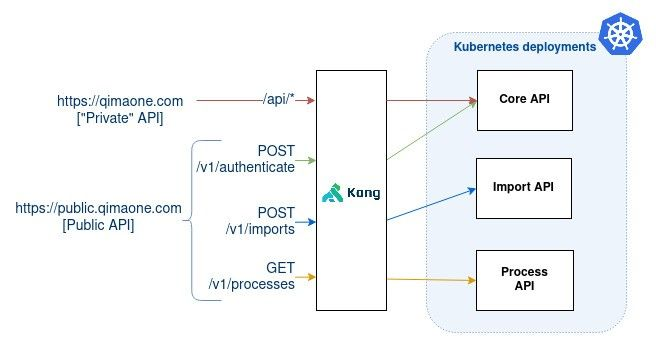
Pros/Cons:
[+] Separate traffic going on Public and Private
[+] Decoupling between customer-facing services and internal infrastructure
[-] Cascading failure on authentication in case the Core API is down
Design outcome
Now, let’s connect the dots of all the steps we have covered:
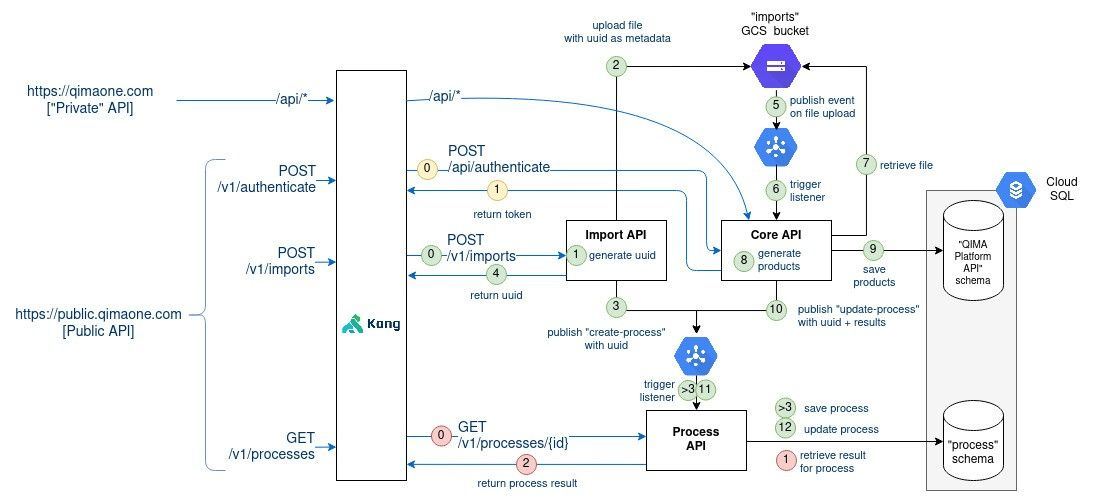
Last words
Some last words regarding the design we have been through. Most choices were made to maximize the availability of the file upload endpoint. Besides, no decision alters the existing business logic and there are only little impact on the application logic.
We must still acknowledge that this design comes with a price: harder to setup developer environment (3 apps instead of 1), more complex build/deployment process, more complex cloud infrastructure.
The final design paves the way for future optimizations:
- Have 2 distinct modes for the “Core API” component: one mode as the back-end for the SaaS (synchronous), one mode to process the files of the import feature (asynchronous). Each mode could live in its own unit of deployment on Kubernetes. When both are deployed, 100% of the features would be ensured. This would reduce the performance coupling components have one another and enable independent scaling.
- Distribute the file processing by splitting the workload and then aggregating the results.
If you want to be part of this adventure, we are currently hiring more Back-End developers! ✨
At QIMA, we relentlessly help our clients succeed. If you have any suggestion or remark, please share them with us. We are always keen to discuss and learn!
Written by Lois Facchetti, Software Engineer at QIMA. ✍️


