
This article is going to give a taste about what is the DevOps mindset in QIMAone team. The DevOps contains all practices that try to ease a Developer and TechOps to work together in order to accelerate/facilitate production. The Techops is incharge to implement infrastructure components and he needs an application to verify that infrastructure fits correctly. The Developer is in charge to implement Business features in the application and he needs the infrastructure to deploy the application and consolidate feature against it.
Some topics, which are strongly related to DevOps, to facilitate the coordination between TechOps and Developers are Continuous Integration/Deployment, Monitoring, Architecture, Support.
Let’s talk about the Continuous Integration this time!
Overview from the top of the mountain
To deploy a version of the application, the team manages 2 repositories on GitHub:
- the first one is for the application code and its docker configuration,
- the second one is for the Kubernetes (aka kube) deployment configuration.
The objective of our CI is to build artifacts which would be used to deploy on the kube cluster (we will discuss this in another article).
Below, the pipeline followed by developers to integrate all development:
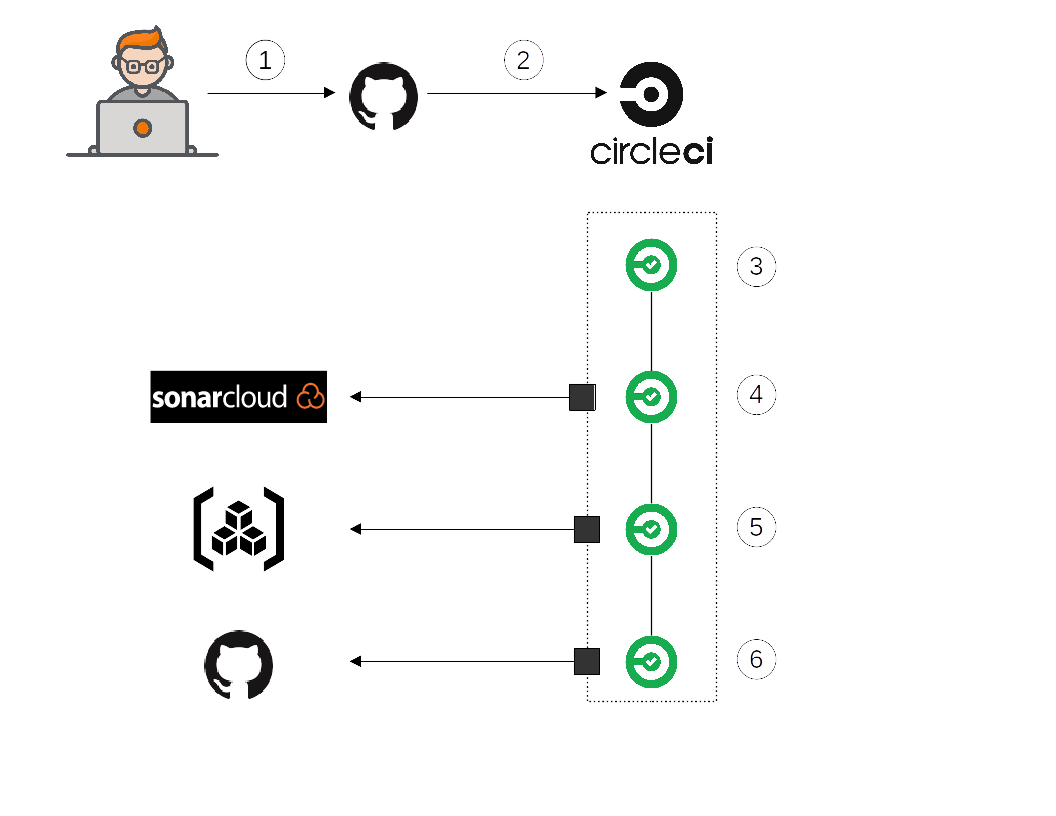
Teams into Github
Like our code is hosted on Github, QIMA uses the organization feature to have the same splitting that we have on the project. So, on QIMAone, there are several developer teams, one ops team and one product team. To give the same weight according to the team during PR review, the splitting was applied in Github.
The common configuration for repository is to have a protected develop branch and to use Pull-Request to integrate new code into develop (like 99% projects on Github and others are heretic).
Access rights to a repository is allocated by belonging to a team and each person is incharge of its branch after creating it.
A good example, Dev teams has read-only access to some Ops repositories (mainly because this is dark side of the infrastructure code 😅). Obviously, Ops and Dev share some repositories to work together.
CircleCI Pipeline
This pipeline is the mostly about waiting to check the PR because, with a red state, the work would not be integrated to the main branch so developers take care that all steps pass correctly.
I. Pull Request: the angular stone
The beginning of the pipeline takes place in Gihub:
- 🔨In the step 1, the Developer works on a PR (obviously based on develop else it’s not fun) by committing frequently code chunk.
- 🚀Then in the step 2, each commit will trigger build workflow in CircleCI (and cancel the previous one in case this one didn’t finish). The target of this PR is to deploy in a sandbox environment so that it can be validated by a Product manager (commonly called Product Owner in Agile methodology) and be reviewed by teams (Dev+Ops).
II. Build and Test
The pipeline implements two different kinds of build, NPM and Maven. So we need two different paths in CI which are executed in parallel. Each path implements the same steps:
- 🏗️ In step 3, the build one, contains the compilation and dependencies downloading for Maven one and, only dependencies downloading for NPM flow. Indeed the transcompilation is done just before the docker image.
- 🧪 In step 4, the test one, each project runs bunch of tests. The project uses differents common test libraries like Jest for our node projects and Junit+Cucumber for Java projects. This one is time-consuming, so all are running in parallel.
Then, a Sonar analysis is applied to gather different metrics on Type Script and Java code. The result is published in the PR.
III. Packaging
During the step 5, front and back-end outputs are packed inside a docker image then the image is published to our private Docker registry (supplied by our Cloud provider obviously). After building images, a security analysis with Trivy is applied to each image so that tracking opened CVE and know if we can apply a patch (mainly image update).
Since the application uses serverless service, CI also creates the bundle through this pipeline to share the same identifier and publish the compressed file on the cloud storage.
All packages shares an identifier respecting this pattern: <stage>-<version>-<commit>
- the first part is the target of the bundle like integration, release or a pull request,
- the last part is a version respecting the SemVer with a version and build information.
IV. Review
This step is primordial in our pipeline because it is the less automated but the place where everyone can share advice, kindness, fear or challenge to the team maintaining the PR. A Sonar review summary is published in the PR to handle as soon as possible any broken standard and improve the code coverage with unit tests. The team doesn’t try to reach 100% of coverage but between 60% and 80% is good and greater than 80% is very good.
The main rule is: each chunk of code merged on develop has to be maintainable by everyone in the team.
To implement a review policy and avoid having code integrated without any validation, some plugins are connected to our Github repository.
First is Policybot, this one is used to ensure that a PR has required reviews according to the changes. To illustrate use, if the PR go to develop, this one needs an approval of at least 2 developers with one from his own team. This one is useful to force/ensure another team like Ops to validate some change, like SQL migration based on the folder path of Liquibase files.
Next one is Mergeable which allows to block a PR until rules are passed. The team uses this one to block “in-progress“ PR. If you put in title or in label the word WIP, the PR will not be mergeable.
Next one is Semantic which ensures that the title respect the semantic of conventional commit. This one is useful because we use semantic release in Release management (which will be the of another article).
Next one is Autolabeler which adds a label when a changes respect a regexp. This one is helpful to alert Ops team when a migration file is modified and their review becomes mandatory. Ops can have permanent link to retrieve PR with the “techops“ label. It’s also used to qualify if the PR is frontend and/or backend. This last one is more to have quick filters for developers according to their craving of application’s side (jedi or sith?).
Next one is DPulls which allows to block a PR until another is merged. It’s useful when you deploy a new component and you need to merge first the kube code before the application one. The other usefulness is to have a reminder directly in the depending PR that the current work is either blocking by another one or splitting on different repository. In real life, it’s when you add an environment variable to you main application but you forgot to merge the related kube code to assign the variable with the good value. Finally, the feature doesn’t work as expected and 5 minutes was lost before you remembered the other PR 🤦. Voilà.
And the last one (but not the least), Mergefreeze which allows to freeze every new merge on the main branch during a defined/arbitrary period. This one is useful in our case to avoid trouble during our automatic release creation which creates a commit but, if you have during this lapse time a new commit, the release process will fail 😤.
V. Trigger Deployment
At the end of the build (in step 6), the last step is a trigger of needed (or not) deployment. If all previous steps are green, this step push a commit into the application kube repository that applies the version in the targeted environment. To select the environment, the developer applies a label to PR to specify it. Without applying any label, the developer can still deploy manually.
Like the pipeline is quite long before reach the deployment step, there are two kinds of CircleCI workflow which is determined also by a label:
- The “build test and push“(by default) workflow that waits all steps to deploy in the environment (around 40 minutes)
- The “build push and test“ one, that triggers the deployment before to run tests but block the PR because the status check of Github expects to run the default one. the app is deployed after 25 minutes.
Time matters
When you start a project, the CI duration is not a concern but, after adding a dozen of developers on it, this concern can become a painful topic when it's combined with speed delivery expectation (🔥). In our case, the build move from 30 minutes to 45 minutes (after making some improvements). To try to keep the build time acceptable by teams, teams (Dev+Ops) try to work frequently on the topic when “the build is too long🐢“ topic appears several times during Agile ceremonies. Some works were done to keep a build time acceptable (without developers riot):
- Externalize our Automated UI testing made with Cypress. Indeed, the project has kept this tests but let manage by QA team. Developers won two things: less time maintaining Cypress tests and reduce the build duration. Now, thanks to QA team, Cypress has its own pipeline to run it against the integration environment.
Like mentioned above, the testing step is time consuming, more features are brought to the application, more tests are implemented. To counter this growth, the team implemented different strategies:
- for Jest, developers put in place more rules around ways to write tests to avoid to load too much stuff through the CDI of Angular. Another one was to follow closer Jest releases publications to benefit sooner of performance improvements in the project.
- for Junit, developers took the decision to avoid as much as possible to create tests with a Spring Boot context even more when the use case is covered by a BDD scenario. The gain is Spring Boot start duration for each test replaced by BDD scenario. In fact, for BDD, Cucumber instantiates only once the Spring Boot context
- CircleCI supplies also some configuration to improve the way to execute a step. The project uses two configurations the shared cache between steps so that they don’t need to download again (and again ) dependencies and the multi nodes features which allows to dispatch and run, in our context, sets of Junit tests in parallel.
To conclude
This big picture of this CI pipeline build+test+deploy has been reached since months, but the content of each step continues to evolve with the project to ensure that we are handling performance issues or adding new tools to analyze the code or reducing our time to deliver. This couple between Github and CircleCI is like two ventricules of heart, if one is down, the other becomes useless and the dev productivity is heavily impacted. The team (Dev + Ops) continuously keeps an eye on it so that the team can continue to move on.
Thank you!
If you want to be part of this adventure, we are currently hiring ! ✨
At QIMA, we relentlessly help our clients succeed. If you have any suggestion or remark, please share them with us. We are always keen to discuss and learn!
Written by Gabriel PASCUAL, Software Engineer at QIMA. ✍️


