
1. Introduction 📖
We are building an awesome application called QIMAone ✨.
QIMAone is a smart and collaborative platform that digitizes quality and compliance management for global brands, retailers, and manufacturers. A key part of our application allows inspectors to do inspections in factories to verify the quality of our customers products.
1.1 Why offline 📵?
In some more remote factories, the internet connection is weak or even non-existent… but the inspector still needs to do their job. Also, inspectors sometimes need to upload several hundred photos and if your connection is slow … having an offline capable application is pretty cool 😎.
1.2 Initial state — On the developer side 🧑💻?
At the beginning, the application was developed without taking into consideration all of its problems that offline could solve. Gradually, we had to convert more features to function offline… We started to have an application working offline, but development estimates to extend the capability were starting to increase…
It was also complex to maintain, without real “consistency” (a lot of IFs everywhere), direct access to our indexed database, in the components and in the services…
To be honest, no real conventions or good practices were shared by the developers. Moreover, the functional need was more complex than just having a simple form to submit. We needed to be able to: download images, store multiple HTTP request, etc. to complete an inspection.

💪
It's time to save time and lose our fear to develop offline features!
1.3 Exploration 🔭
This adventure started with exploration. After exploring for a while, we realized that the magic library which would answer all our needs didn’t exist. We also found some articles, but none allowed us to start with a solution ready-to-go.
Our first idea was to create our solution, a new architecture and reuse some existing processes. This solution needed to be able to stock the data in an IndexedDB and synchronize all user actions.
We had the opportunity to discuss with some experts in web development (Emmanuel DEMEY, Jeff GARREAU). Some good ideas came from those exchanges, but everything was really complex. We anticipated some navigator compatibility problems (Background Sync), technical issues (PouchDB) if we went this path.
By now, we knew then that our first idea, a home-made solution, was the right one. The time had come for us to jump-in! 👨🏻💻
2. The solution! 🏗
To avoid our past mistakes, we were determined to keep it as simple as possible, with a maintainable architecture and clearly identified but distinct needs
Taking all these points into account, we started by creating several diagrams. The set of possible solutions was presented to the whole team during a “Front Exchange” and we voted for this…👇
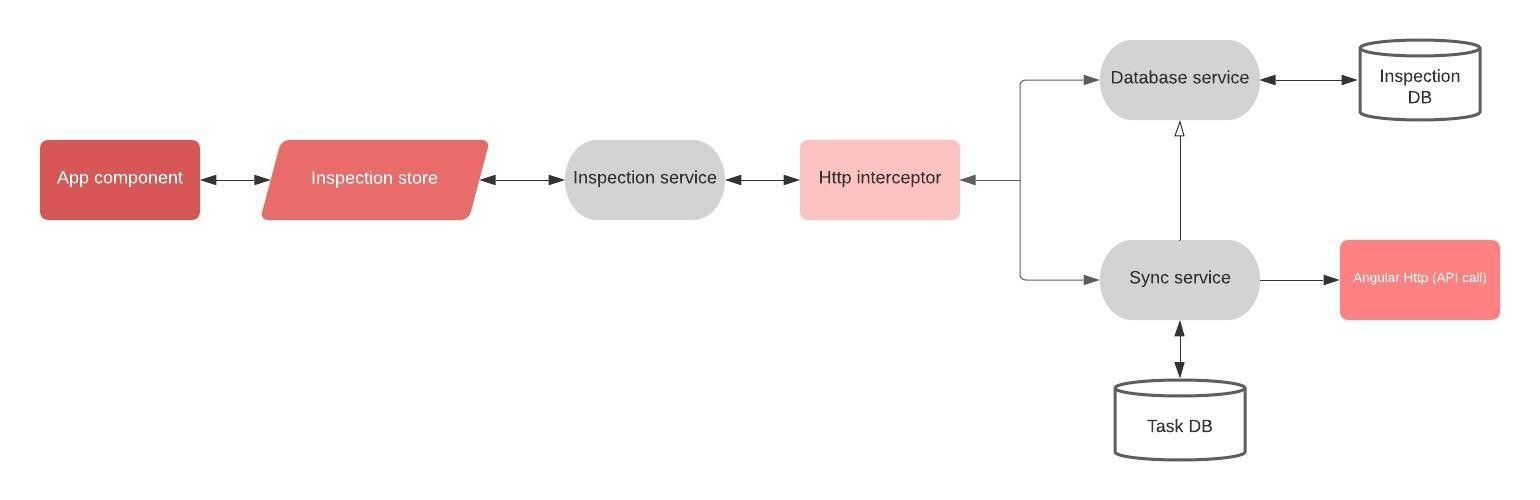
With our target solution defined, we could divide-and-conquer each architectural component!
Front Exchanges
Every 2 weeks, developers discussed new features, new libraries, implementations, … and planned future implementation (like the offline architecture)
In short, it's a good moment of sharing tech-talk between all the developers!
3. What about the code ✏️ ?!
3.1 Store with NgRx → A strict process 💪
In the past, we had discussed of using this library, but then we decided to hold off. A simpler solution of a store class, which used BehaviorSubject to dispatch events looked better.
Now, we decided to go revisit our decision to add the library. We needed a way to ensure the coherence of the data in the entire application and hence we went for NgRx.
 ngrx
ngrx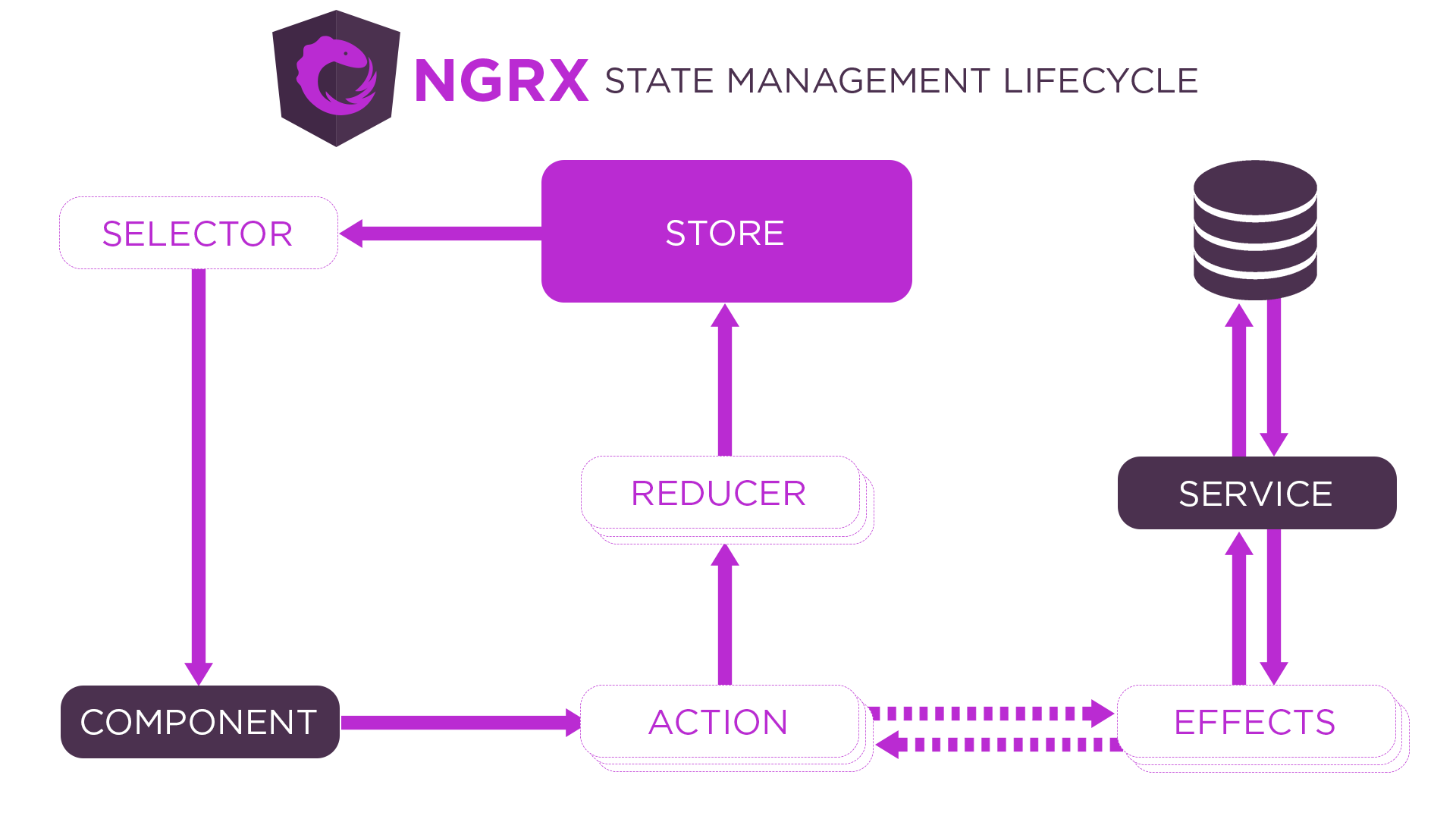
Component
Dispatches the event when something happens on the app.
e.g., when the user answers a question.
this._store.dispatch(fromWorkflow.saveTestAnswer({
id: this.element.id, value
}));Action
Describes unique events that are dispatched between the component, reducers, and effects
export const saveTestAnswer = createAction(
SAVE_TEST_ANSWER, props<{ id: string; value: Answer }>()
);Effects
Receive the action data and invoke service.
⚠️ The effect should return “an effect success condition”,
e.g., after calling the inspection service, the effect will return the object as shown below
{
type: SAVE_TEST_ANSWER_SUCCESS,
id: action.id,
value: action.value,
};
It means that everything is OK, effect and reducer can take the action values and update the current state
️️️⚠️ Sometimes the effects will push other actions too.
e.g., updateInspectionStatus$ action which forces a workflow loading after the status update
if (action.status === InspectionStatus.ACCEPTED) {
actions.push({
type: LOAD_WORKFLOW,
id: action.id,
});
}
return actions;Reducer
Update the store according to the action
on(fromWorkflow.saveTestAnswerSuccess, (state, { id, value }) => {
const workflow = cloneDeep(state.workflow);
const element = WorkflowUtils.getTestById(workflow, id);
element.value = value;
return {
...state,
workflow,
};
}),Subscription
Be notified of data change on store
this._store
.pipe(
select('inspectionStore'), // select the store to watch
select('inspection'), // select the specific data
filter((val): boolean => null !== val), // filter on not null result
select('id') // select only the inspection id
)
.subscribe((id: number): void => { // subscribe to be notify on each changes
this._inspectionId = id;
});
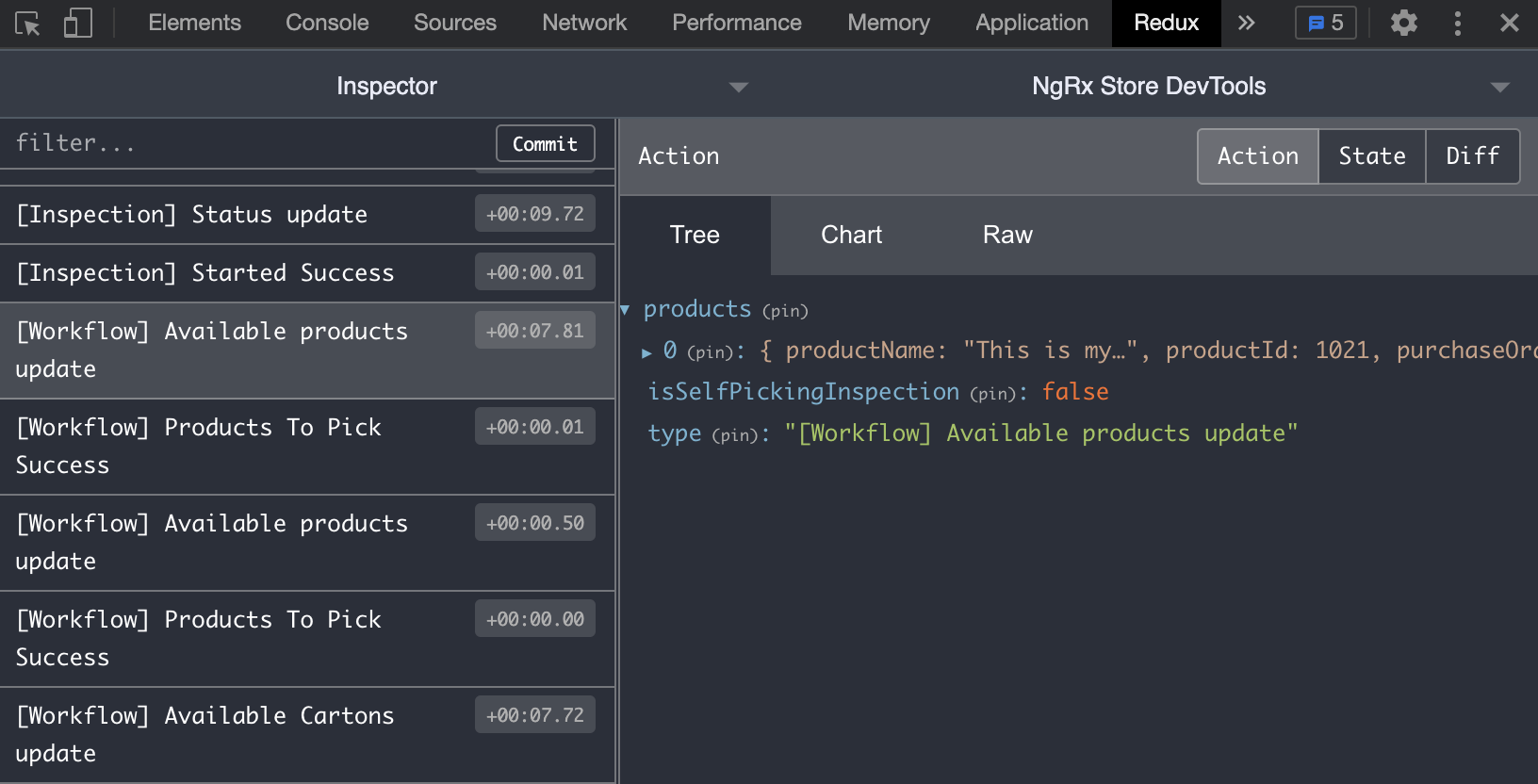
NB: NgRx is a wonderful library, but developing with it can sometimes be hard. It’s complicated to know what's going on behind … but for that, there is a useful browser extension called Redux

Redux lets developers know what's going on. We got a notification every time an NgRx event appears with the possibility to preview the event’s content 👌
3.2 Services: Stay like it is 🥶!
The services are state agnostic. They don’t know whether is user is offline or online. The services are simply called by the store effects and send the HTTP requests as usual to the API. 👌

3.3 Interceptor: Catch all 🥅!
Interceptors allow us to intercept the request from services and act based on the network state. We use an Angular interceptor to intercept and execute the HTTP requests.
@Injectable()
export class MyBeautifulInterceptor implements HttpInterceptor {
intercept(
request: HttpRequest<any>,
next: HttpHandler
): Observable<HttpEvent<any>> {
// We can here edit, cancel... the request
// ....
return next.handle(request);
}
}The interceptor needs to catch all the requests sent by the application. So, in terms of writing and usage, these classes can quickly become unreadable.
⚠️ We work in an “offline first” mode. It means that for every request, the interceptor will try to do everything locally first. If a result already exist in the indexed database, we use it!
There are two types of requests:
- “read-only” (GET)
The interceptor will get the data from the local DB and return it. - Update, save requests (POST, PUT, PATCH, DELETE)
The interceptor needs to create an action. These actions are different from the NgRx ones. It sends the action to the ActionQueue service that is responsible for the synchronization.
NB: Sometimes we had to call the API directly, skipping the offline-first mode. To achieve that, we simply used a header X-Skip-Interceptor
public intercept(request: HttpRequest<any>, next: HttpHandler): Observable<HttpEvent<any>> {
if (request.headers.has(InterceptorSkipHeader)) {
return next.handle(request);
}
// ...
}3.4 Store the data using Indexed Database API 🏬:
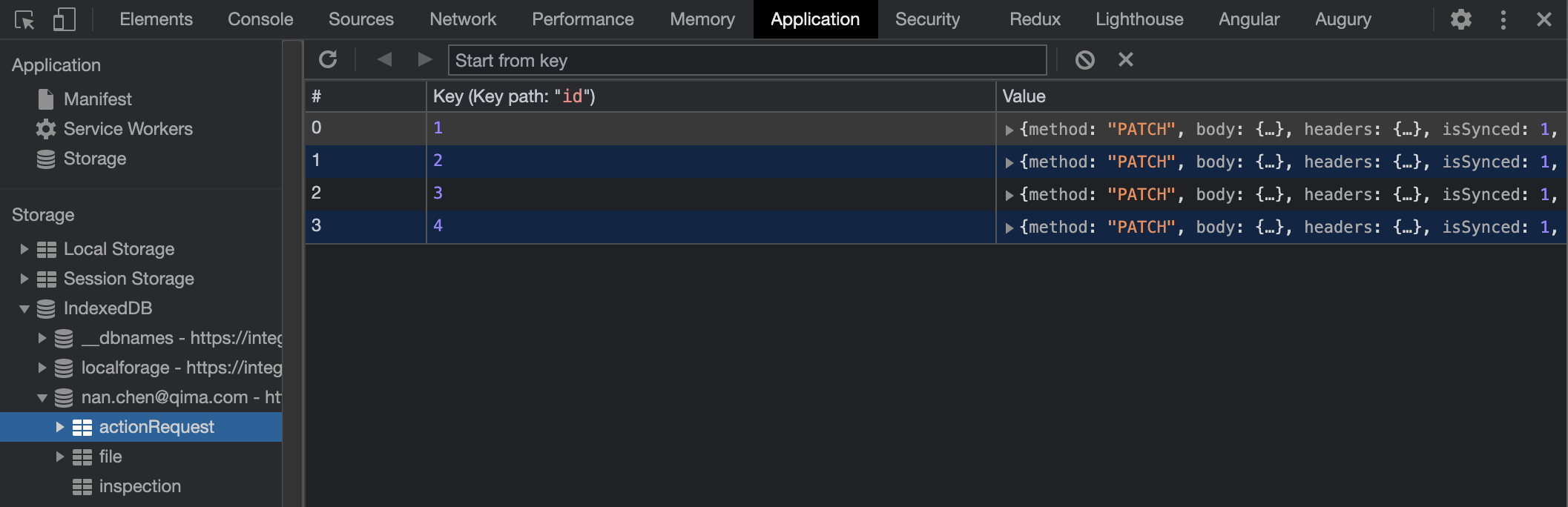
For the local database we use IndexedDB, a local indexed database in the browser. Here are the advantages :
- Well supported by the modern browser
- Asynchronous
- Support the indexes
The main challenge is that the default API for the standard IndexedDB is not easy to use and maintain. So, we decided to use a wrapper named Dexie.js.
Dexie.js 💪

Dexie.js is a minimalistic indexed DB wrapper that provides near-native performance, and it's easy to use it. The package size is around 22 KB 🤩 and it works cross-browser and devices. It solves error handling via promises rather than events, so less coding and more maintainable code.
To avoid a huge number of tables, we decided to go with a simple storage model with a generic part:
- A table for the inspection’s data and the inspection itself.
- A table for the workflow of the inspection.
- A dedicated table for all the files (PDF documents / Inspection pictures / Scans / …).
- A table to save the HTTP requests (let's talk more about this important table after)
At this point in the story we have the library to interact with the database, the future storage model, and it is easy to initialize our database service with Dexie.js 👇
export class Database extends Dexie {
public inspection: Dexie.Table<IInspection, number>;
public workflow: Dexie.Table<IWorkflow, number>;
public actionRequest: Dexie.Table<ActionRequest, number>;
public file: Dexie.Table<InspectionFile, number>;
public constructor(databaseName: string) {
this.version(1)
.stores({
inspection: '&id',
workflow: '&id',
file: '++id,&fileId',
actionRequest: '++id,isSynced',
});
// ...
this.inspection = this.table('inspection');
/// ...
}
} First step of the initialization is to define the Dexie model of your database, specifying:
- A version.
- A list of the tables and the associate schema syntax.
A quick view of our Database service using the Dexie.js configuration 👇
class DatabaseService {
public constructor() {
this.database = new Database('inspector@qima.com');
}
public async getInspections(): Promise<IInspection[]> {
return await this.database.inspection.orderBy('id').reverse().toArray();
}
}Data migration 🚨
Between any two releases, the API can change! So, we have to deal with the case where an inspector starts the inspection in offline mode with an old version API and then triggers the synchronization, after an API change. How to avoid a breaking change?
With Dexie.js, there is the possibility to define a version of our data and migrate them if needed: https://dexie.org/docs/Dexie/Dexie.version()
Here is an example of a migration 👇
/**
* In the version 13
* We need an inspection id on the file items
* For generic file (file without inspection) we decide to set default id to 0
* due to Dexie not accepted null type. 😢
* To do that we loop over all files
* and if inspectionId does not exist we put 0
*/
this.version(13)
.stores({
file: '++id,inspectionId,&fileId',
})
.upgrade(trans =>
trans
.table('file')
.toCollection()
.modify(file => {
file.inspectionId = file.inspectionId || 0;
})
);With this feature we have the possibility to deal with an out-of-sync application and be ready to successfully synchronize after an upgrade 😀
3.5 Synchronize the data ♻️
For the request that updates the data (POST, PUT…) it’s necessary to save the request in the local database to be able to send it in the future when the network is back. In fact, when the user’s network is back we cannot parallelize the requests because the request order is important for our application. We need to know, even if an action is done offline, the time and the time zone!
There are 2 services to do it:
- ActionQueueService: This service aims to manage the actions’ list to synchronize. The interceptor pushes the actions and the service keeps it in the queue. To prevent the user refreshing his web browser cache and losing everything, this queue is saved in the indexed database.👇
class ActionsQueueService {
private readonly _queue: ActionRequest[] = [];
private readonly _addRequestSubject$ = new Subject<HttpRequest<any>>();
public get queue(): ActionRequest[] {
return this._queue;
}
public get addRequestObservable(): Observable<HttpRequest<any>> {
return this._addRequestSubject$.asObservable();
}
public addAction(request: HttpRequest<any>): void {
this._addRequestSubject$.next(request);
}
}- ActionQueueSyncService: This service is connected to the ActionQueueService and manages the synchronization with the back-end. The service listens the network status, When the connection is back, it tries to send the requests one by one. 👇
class ActionsQueueSyncService {
private _isSyncing = false;
private _fetchActionsFromDb: Promise<void>;
public constructor(
private readonly _http: HttpClient,
private readonly _dbService: DatabaseService,
private readonly _networkStatus: NetworkStatusService,
private readonly _actionQueue: ActionsQueueService,
private readonly _inspectionCleanService: InspectionCleanService
) {}
public init(): void {
this._dbService.retrieveActionRequests().then(actions => {
this._actionQueue.queue.push(...actions);
if (actions.length > 0 && !this._isSyncing) {
void this.synchronize();
}
})
);
}
public async synchronize(): Promise<void> {
this._isSyncing = true;
const isOnline = await this._networkStatus.isOnlineOnce.toPromise();
if (!isOnline) {
this._isSyncing = false;
}
while (this._actionQueue.queue.length > 0) {
const action = this._actionQueue.queue[0];
await this._http.request(request).toPromise();
this._dbService.markActionRequestAsSynced(action);
this._actionQueue.queue.shift();
}
this._isSyncing = false;
}
}Tricky part:
- When we saved a request in the database we needed to remove the security headers (like the JWT token) otherwise there was a risk of security breach 🚨.
public removeSensitiveHeaders(action: HttpRequest<any>): HttpRequest<any> {
return new HttpRequest(action.method, action.url, action.body, {
headers: action.headers.delete('authorization'),
params: action.params,
responseType: action.responseType,
});
}- For an HTTP request which contains files like images, we load the file only when it’s necessary to reduce the memory footprint.
3.6 Preload the data ♻️
Some of our inspections have process stages with documents, files useful for the inspector. If we assume that the inspector starts his inspection in a state of slow or no connection, he will not be able to access these files…
This is why we set up a preloading service for the files linked to an inspection.
This service is called as soon as the inspector accepts the inspection (action only possible in a connected state).
We just have to loop over each file, call the service, let the awesome inspection interceptor trigger the call and save the data in the database 👌
export class InspectionPreloadService {
// ...
public preloadDocuments(workflow: IWorkflow, inspectionId: number) {
const fileIdList = WorkflowUtils.getFileIdListByWorkflow(workflow);
fileIdList.forEach((fileId: string) => {
this.inspectionService.getDocument$(inspectionId, fileId).subscribe();
});
}
}NB: we can just have a .subscribe() to trigger the call, we don't care about the getDocument$ result
3.7 Service Worker 👷
Service Workers essentially play the role of proxy servers placed between a web application and the browser or network (when available.)
They are intended to enable the creation of an efficient offline browsing experiences, by intercepting the network requests and taking appropriate actions depending on whether the network is available and updated resources are available on the server.
One other feature of the service workers is the ability to save a list of files to the cache while the service worker is installing. This is called “pre-caching”, since you are caching content ahead of the service worker being used.
At the beginning of the project, we generated the stack using JHipster, and it provided by default Workbox for the PWA part.


Workbox is a library that bakes-in a set of best practices and removes the boilerplate every developer writes when working with service workers, it includes some “features“ like:
- Precaching
- Runtime caching
- Strategies
- …
In our case, we used the Workbox precaching feature to prefetch all the assets even if the user doesn't visit and download some parts of the app. Thanks to this, the user will simply have to:
- login once
- move to a place without connection
- enjoy the offline mode 😀
Spoiler 🚨
We plan to moved to @Angular/PWA, but let's talk about it in another blog post 😅
3.8 Some cleaning to do 🧼
Having all the data in offline is cool 😎! But, a limit for the offline in a PWA is the storage usage… especially on a mobile! 📱 We don't have infinite storage space on our phones. If there is not enough memory on the phone, it won’t be possible to continue and complete the inspection.
Some information about the browser storage limit : 🔗 Browser storage limits and eviction criteria
The idea is have several cleaning solutions because space is important 😅.
The main thing to know is that normally for an inspector it is very rare to go back over a completed inspection. Based on this assumption, we can set up a method which will be called when we sync the request about inspection completion.
We just have to add a condition inside our dear ActionQueueService 👇
@Injectable({
providedIn: 'root',
})
export class ActionsQueueSyncService {
//...
public async synchronize(): Promise<void> {
//...
/**
* If is the last action of an inspection (completed status)
* Call cleanInspection with the inspection id 🧼
*/
if (
request.method === 'PATCH' &&
InspectionInterceptor.PATCH_INSPECTION_STATUS_REGEX.test(request.url) &&
request.body &&
request.body.status === InspectionStatus.COMPLETED
) {
await this._http
.request(request)
.toPromise()
.then(() => {
void this._inspectionCleanService.cleanInspection(
+request.url.match(InspectionInterceptor.PATCH_INSPECTION_STATUS_REGEX).groups.id
);
});
}
//...
}
}And call the InspectionCleanService cleanInspection method 👇
export class InspectionCleanService {
//...
public async cleanInspection(id: number) {
await this.dbService.deleteInspectionsFiles([id]);
await this.dbService.deleteWorkflows([id]);
await this.dbService.deleteInspections([id]);
}
}
We have also implemented, in addition to cleaning at the end of an inspection, an automatic cleaning action called each time the application is loaded in the browser.
In the clean method, we have to:
- Get all the inspections stored in the local database
- Filter on inspections done more than 3 days ago
- Call the delete methods of database service for each “entity”:
- Files 👉
this.dbService.deleteInspectionsFiles(ids); - Workflow 👉
this.dbService.deleteWorkflows(ids) - Inspection 👉
this.dbService.deleteInspections(ids); - Action Requests 👉
this.dbService.deleteSyncedActionRequests(...);
export class InspectionCleanService {
public DAYS_BEFORE_CLEAN = 3;
constructor(private readonly dbService: DatabaseService, private readonly dateService: QpDateService) {}
public async clean() {
await this.dbService.isDBInit.toPromise();
let inspections = await this.dbService.getInspections(); // 1.
const ids: number[] = inspections // 2.
.filter(insp => {
if (InspectionStatus.COMPLETED !== insp.status)) {
return false;
}
if (this.dateService.howManyDaysAgo(insp.inspectionDate) >= this.DAYS_BEFORE_CLEAN) {
return true;
}
return false;
})
.map(insp => insp.id);
// 3.
await this.dbService.deleteInspectionsFiles(ids);
await this.dbService.deleteWorkflows(ids);
await this.dbService.deleteInspections(ids);
await this.dbService.deleteSyncedActionRequests(this.DAYS_BEFORE_CLEAN);
//...
}
//...
}🤷
There are some suggestions
We started by just implementing a clean service in our app, but we can improve it more using the Storage API.

The Storage API gives the ability to determine how much storage space the app can use, how much it’s already using, and even be alerted before the user's web browser erases data to free some memory that can be useful for something else.
A simple snippet of the usage 👇
navigator.storage.estimate().then(estimate => {
// estimate.quota is the estimated quota
// estimate.usage is the estimated number of bytes used
});We could also have added features, like adding a button to clean the local data in the settings page, display the estimated quota of storage usage, but let's save some work for later 😅!
4. Conclusion
Having our inspector application running offline is something we realize, more and more, is important. It sounds simple to us, but finding the perfect solution is not easy. This solution that we have presented to you may not be the perfect solution, but it meets all our needs and can easily be upgraded!
This solution has been in production for a few months, and for the moment we have no negative feedback, we had some concerns about the limitations of devices (phone used in China) and the storage limitations. But everything is under control!
As soon as this solution was put online, we had positive feedback from our final users who saw a big difference, especially on the file upload 😅 (no need to wait for the upload to the API which could take a long time on slow connections). Nice to have this feedback after several months of refactoring!
We still have a lot of work to do. To develop this solution, we took some shortcuts. We took care to create technical tasks to remember to improve some (functional) parts. We also have many ideas to improve our code and the UX of our solution like:
- Using Storage API and display some alerts.
- Displaying in the application, the state of the synchronization for when the connection is back.
Thank you!
If you want to be part of this adventure, we are currently hiring more Front-End developers! ✨
At QIMA, we relentlessly help our clients succeed. If you have any suggestion or remark, please share them with us. We are always keen to discuss and learn!
Written by Loyer Aurelien, Software Engineer at QIMA. ✍️


